Обновление до последней версии Dynatrace
- Классический
С последней версией Dynatrace вы получаете значительные улучшения в хранении и анализе данных наблюдаемости, безопасности и бизнес-данных.
Чтобы воспользоваться этими улучшениями, вам необходимо адаптировать конфигурацию хранения данных, доступа к данным и сегментации. Эта статья проведет вас через лучшие практики настройки хранения данных и контроля доступа к данным в Grail.
Что вы узнаете¶
Это руководство предназначено для администраторов Dynatrace с окружениями на AWS или Azure.
С помощью этого руководства администратор Dynatrace может настроить Dynatrace и Grail и предоставить своим командам доступ к новым функциональным возможностям, таким как AppEngine, AutomationEngine или Notebooks.
Существующая функциональность остается прежней
Обратите внимание, что эти адаптации применяются только к использованию новой и улучшенной функциональности, называемой «Последняя версия Dynatrace». Существующая функциональность не затрагивается этими адаптациями.
Что нужно знать в первую очередь¶
Прежде чем приступить, вам необходимо ознакомиться с концепциями, которые обеспечивают новую ценность, которую мы называем последней версией Dynatrace.
Последняя версия Dynatrace — это комбинация взаимосвязанных новых функций, которые обеспечивают улучшения в хранении и анализе данных наблюдаемости, безопасности и бизнес-данных.
Grail¶
Одним из основных изменений является внедрение Grail в качестве нового унифицированного хранилища данных. Grail дает вам значительные улучшения в загрузке, хранении и аналитике данных. Далее вы узнаете, как настроить хранение данных и контроль доступа к данным в Grail.
Подробнее см. Grail.
Язык запросов Dynatrace¶
Grail не только хранит все данные наблюдаемости и безопасности, но и обеспечивает доступ к этим данным с помощью языка запросов Dynatrace (DQL). Доступ ко всем данным через язык запросов является новым для Dynatrace и выходит далеко за рамки доступа к данным через API и пользовательские интерфейсы, которые мы предлагали ранее.
Подробнее см. Язык запросов Dynatrace
Множество способов доступа и анализа данных¶
Вместе с внедрением Grail компания Dynatrace также выпустила набор значительных улучшений пользовательских интерфейсов, API и сервисов.
Внедрение Notebooks, Workflows и новых Dashboards позволяет вам получить доступ к данным в Grail различными способами. Это варьируется от использования готовых представлений от Dynatrace или коллег до создания высокоспециализированных представлений. Кроме того, вы можете реализовать собственную логику с помощью полностью настраиваемых приложений, работающих на AppEngine. Любая мыслимая операция с данными Dynatrace становится возможной.
Однако прежде чем пользователи без прав администратора смогут использовать новейшие функции Dynatrace, необходимо выполнить несколько административных шагов для управления доступом к данным. Они описаны ниже.
Переход на новый интерфейс¶
Ваши пользователи уже имеют возможность переключиться на новый пользовательский интерфейс, хотя большая часть его функциональности основана на существующих представлениях, которые по-прежнему используют текущие концепции управления: зоны управления и разрешения.
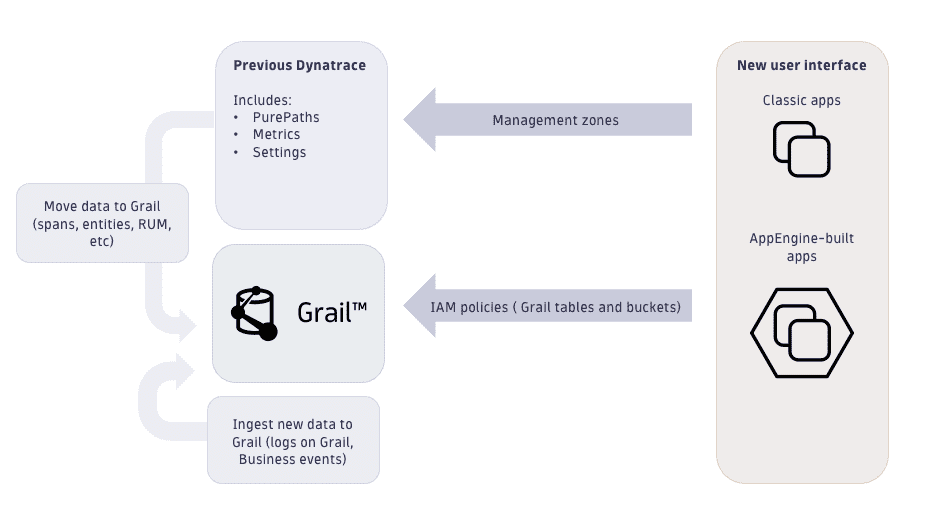
Контроль доступа¶
В чем разница между зонами управления и новыми политиками IAM?¶
Текущая концепция зон управления : Косвенно контролирует доступ к данным мониторинга (распределенные трассировки и метрики) на основе идентификаторов сущностей.
Политики безопасности для доступа к данным в Grail : Контролирует доступ к данным мониторинга на основе полей, значимых для безопасности, и вновь введенного контекста безопасности.
Хотя зоны управления являются очень универсальным инструментом для настройки сложных разрешений, эта гибкость также оказалась узким местом в крупных корпоративных средах, хранящих большие объемы данных. Для успешного использования зон управления загружаемые данные должны быть связаны с мониторируемой сущностью. Управление доступом к данным с Grail основано на данных, типе данных и организации данных. Политики безопасности могут быть определены для предоставления доступа только к определенным данным даже без связи с какой-либо сущностью.
Стандартные поля, значимые для разрешений, могут использоваться в большинстве случаев для контроля доступа. Кроме того, мы добавили поле dt.security_context, которое зарезервировано для деталей, специфичных для окружения. Все компоненты Dynatrace обеспечивают наличие этих полей разрешений, относящихся к таблице, в каждой записи (событии, логе, спане) или метрике. Это позволяет создать единую концепцию разрешений для всего окружения.
Подробнее см. Управление идентификацией и доступом (IAM).
Данные в Grail¶
Модель данных Grail состоит из корзин, таблиц и представлений Grail.
- Таблицы описывают тип данных наблюдаемости.
- Корзины Grail являются контейнерами хранения, подобно папке в файловой системе.
- Каждая корзина назначена таблице, поэтому группа таблиц имеет несколько корзин. Извлечение записей из таблицы означает, что опрашиваются все корзины.
Свежее окружение Dynatrace поставляется с несколькими корзинами по умолчанию. Эти корзины имеют префикс default_ и не могут быть изменены. В процессе настройки окружения пользователи могут определять пользовательские корзины (как описано далее).
Загрузка данных в Grail начинается с OneAgent или одного из наших API загрузки:
Доступ к данным Grail через DQL¶
Данные, хранящиеся в Grail, доступны через DQL. Самый простой способ впервые просмотреть данные — использовать Notebooks.
Логи, события и бизнес-события¶
Логи, события и бизнес-события используют собственные таблицы с корзинами по умолчанию и хранением в течение 35 дней. Вы можете получить к ним доступ с помощью следующих команд в разделах DQL блокнота:
Трассировки¶
Трассировки определяются спанами, а корзина по умолчанию для спанов хранится в течение 10 дней. Просмотрите раздел фрагментов кода в блокноте для быстрого старта или исследуйте с помощью:
Спаны находятся в предварительной версии и доступны не на всех окружениях сразу.
Топология¶
Топология (мониторируемые сущности) пока не хранится в Grail. Вместо этого классическое хранилище сущностей доступно через DQL через предопределенные представления с префиксом dt.entity.
Метрики¶
Многие метрики уже по умолчанию хранятся в Grail. Список расширяется каждый месяц. Метрики хранятся в течение 15 месяцев. Вы можете легко получить к ним доступ через обозреватель метрик в блокноте или с помощью команды timeseries, как в примерах ниже:
Системные данные Dynatrace¶
Grail также хранит системные данные Dynatrace, которые вы можете исследовать. Например, вы можете увидеть, какие таблицы и корзины определены, и проверить системные события, такие как события аудита.
dt.system.data_objects— список всех таблиц и представлений.dt.system.buckets— отображает все определенные корзины.dt.system.events— содержит события, генерируемые окружением, такие как события аудита.dt.system.query_executions— представлениеdt.system.eventsдля быстрого доступа к выполнению запросов. Оно позволяет администраторам видеть, кем и какие запросы выполняются.
Кто может получить доступ к данным?¶
Доступ к данным контролируется через политики безопасности вместо зон управления. В целом существует два уровня контроля доступа: доступ к корзинам и доступ к таблицам. Чтобы пользователь мог получить запись, ему нужен доступ к корзине, в которой хранится запись, и к таблице, к которой назначена корзина.
Например, пользователь, который хочет получить доступ к записям логов из корзины default_logs, нуждается в следующих двух разрешениях:
ALLOW storage:logs:readALLOW storage:buckets:read WHERE storage:bucket-name = "default_logs"
Администраторы получают автоматически назначаемые политики, которые позволяют им использовать новую платформу и запрашивать все данные через блокноты. Для других пользователей администратор сначала должен назначить соответствующие политики (например, применив AppEngine User для доступа к блокнотам и Storage All Grail Data Read для получения данных). В зависимости от данных в вашем окружении на первом этапе вы можете использовать политики по умолчанию.
Встроенные политики¶
Dynatrace поставляется с набором встроенных политик для доступа к данным. Все они имеют префикс Storage:
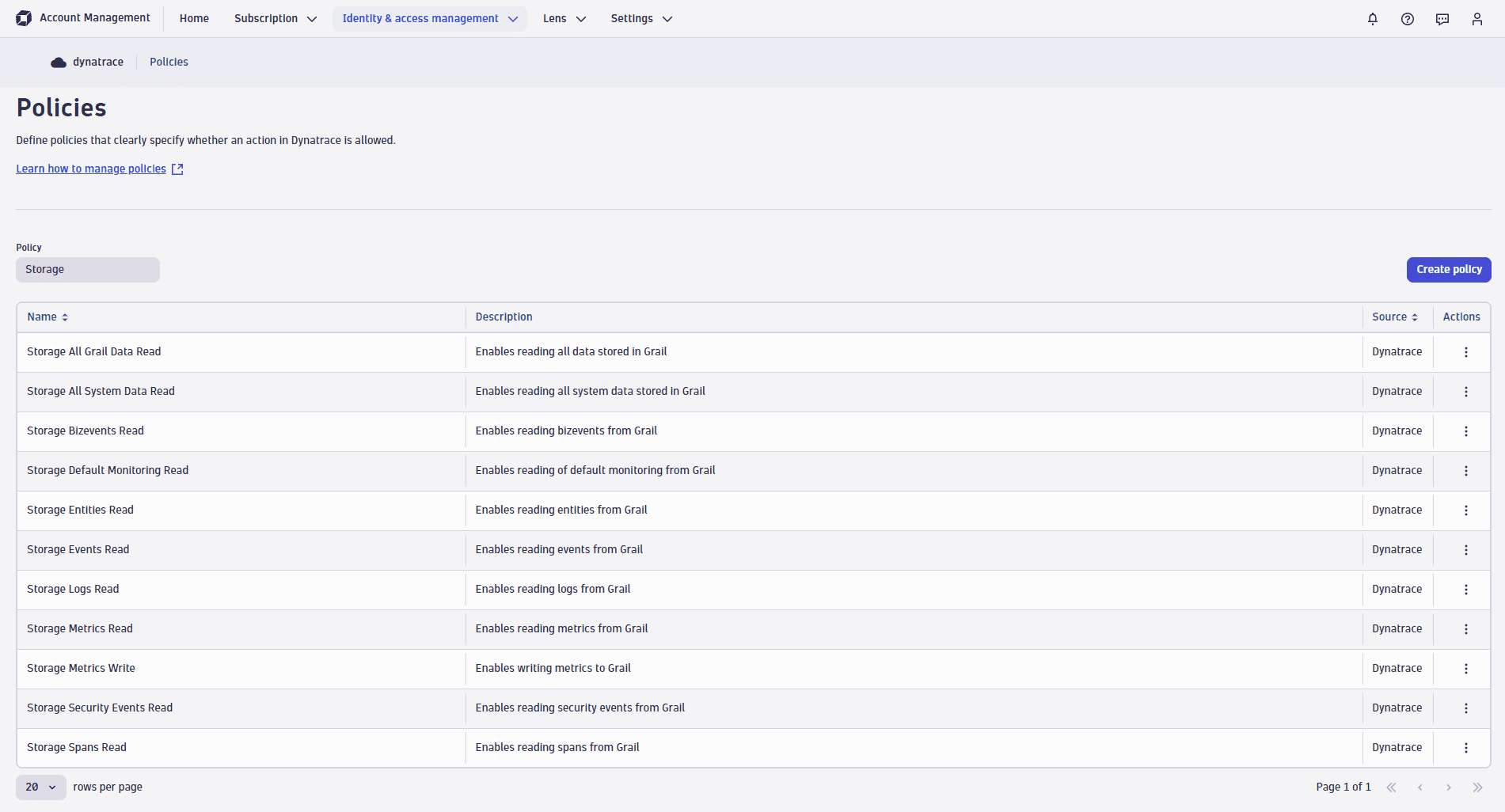
Например, посмотрите на политику Storage Default Monitoring Read, которая предоставляет следующие два разрешения:
ALLOW storage:buckets:read WHERE storage:bucket-name STARTSWITH "default_;"
ALLOW storage:events:read,storage:logs:read,storage:metrics:read,storage:entities:read,storage:bizevents:read,storage:spans:read;
Это предоставляет пользователю доступ ко всем таблицам и всем корзинам по умолчанию (которые имеют префикс _default). После создания пользовательских корзин пользователям необходимо получить явный доступ для работы с ними.
Примечание: Все встроенные политики предоставляют безусловный доступ к таблицам. Как только вы начнете использовать разрешения на уровне записей, вам нужно будет заменить политики по умолчанию собственными политиками.
Разрешения на уровне записей¶
Доступ к данным может быть дополнительно ограничен на основе полей разрешений. Это достигается добавлением условия WHERE к разрешениям таблицы. Например, предоставление пользователю доступа только к логам определенной группы хостов может быть достигнуто путем предоставления следующего разрешения:
ALLOW storage:logs:read WHERE storage:dt.host_group.id = "myhostgroup"
Имейте в виду, что все разрешения, назначенные пользователю, будут оценены.
Если пользователь уже получил доступ ко всем логам через безусловное разрешение ALLOW storage:logs:read;, это имеет приоритет, и разрешение на уровне записей не будет иметь эффекта.
Подробнее о разрешениях на уровне записей:
Контекст безопасности¶
Поле dt.security_context не заполняется автоматически компонентами Dynatrace. Его можно свободно использовать для добавления пользовательского измерения к разрешениям на уровне записей, которое не отражается другими полями разрешений. Если вам нужно ограничить доступ по полям, которых нет в таблице поддерживаемых полей, вам необходимо установить dt.security_context при загрузке данных.
Приступим к работе: реализация контроля доступа к данным¶
Реализация контроля доступа к данным требует двух наборов действий:
- Планирование разрешений доступа к данным путем определения деталей, на которых можно основать концепцию контроля доступа.
- Организация данных в корзины для дополнительного контроля доступа и пользовательских периодов хранения.
Планирование разрешений доступа к данным для вашего окружения¶
Сначала вам нужно определить детали, которые вы будете использовать для контроля доступа. Примерами могут быть идентификаторы или названия продуктов, команды или другие организационные детали. Обычно эти детали уже смоделированы, например, через группы хостов Dynatrace или пространства имен Kubernetes. Следующая блок-схема показывает, как определить концепцию разрешений для ваших данных.
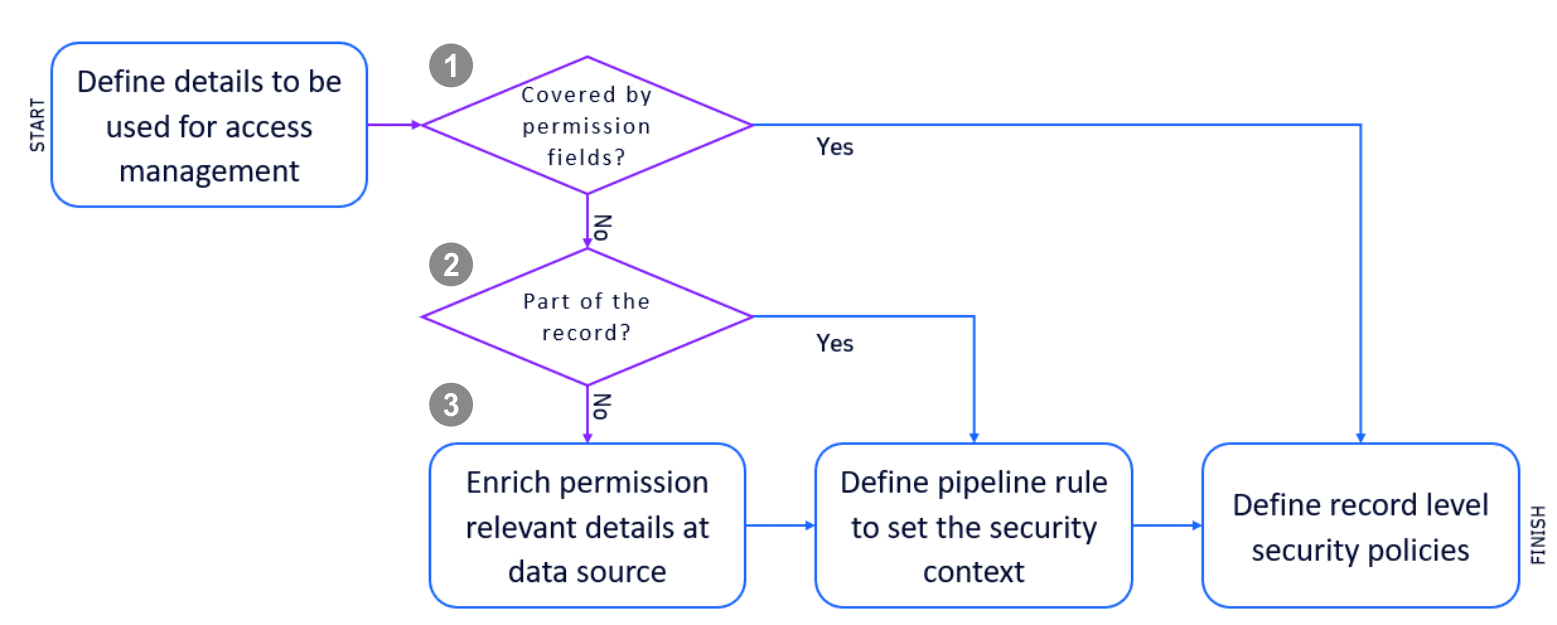
Шаг 1. Контроль доступа через условия IAM¶
Если поля разрешений уже покрывают необходимые детали, вы можете перейти к определению разрешений на уровне записей.
| Имя поля | Условие IAM |
|---|---|
event.kind |
storage:event.kind |
event.type |
storage:event.type |
event.provider |
storage:event.provider |
k8s.namespace.name |
storage:k8s.namespace.name |
k8s.cluster.name |
storage:k8s.cluster.name |
host.name |
storage:host.name |
dt.host_group.id |
storage:dt.host_group.id |
metric.key |
storage:metric.key |
log.source |
storage:log.source |
dt.security_context |
storage:dt.security_context |
Шаг 2. Контроль доступа через запись¶
Очень часто детали уже доступны в записи, но не в одном из полей разрешений.
Например, файлы логов могут содержать детали в своем содержимом. В таких случаях вы можете использовать конвейер загрузки для установки контекста безопасности на основе любых деталей входящей записи. Следующая иллюстрация показывает, как использовать выражение сопоставления DQL для содержимого лога для определения контекста безопасности на его основе.
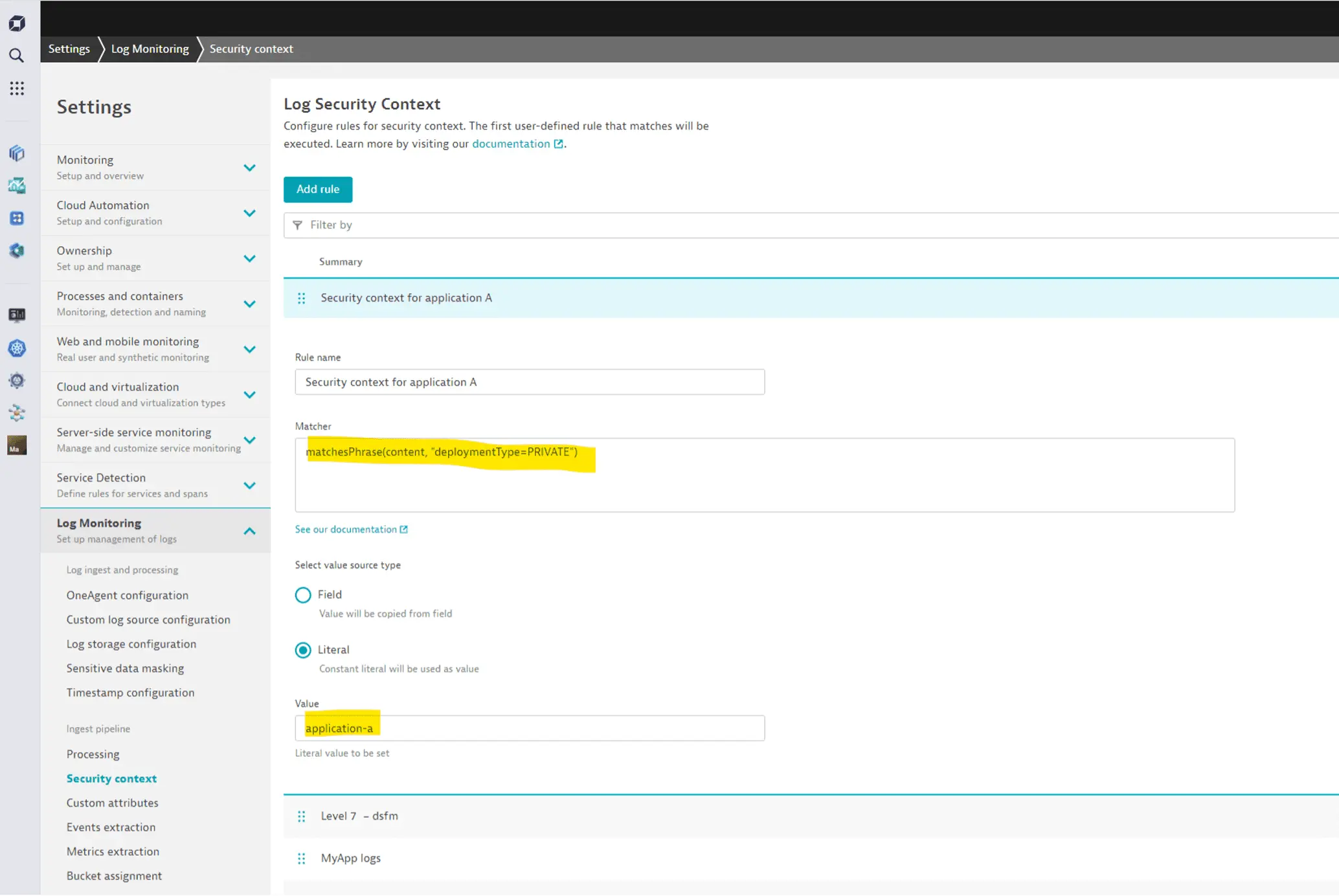
Подробнее см. Настройка разрешений Grail для логов.
Шаг 3. Контроль доступа через пользовательские детали¶
В случаях, когда детали еще не являются частью записи, вам нужно будет изменить источник данных.
У вас есть два варианта:
- Установить поле контекста безопасности непосредственно в источнике.
- Включить деталь в любой другой форме и использовать правило конвейера для установки поля контекста безопасности.
Организация данных¶
Чтобы раскрыть полный потенциал Grail, вы также можете использовать пользовательские корзины для управления данными мониторинга. Пользовательские корзины служат следующим целям:
- Хранение данных: различные сроки хранения требуют разных корзин.
- Разделение данных и контроль доступа: хранение данных в разных корзинах сравнимо с хранением данных на разных дисках. Контроль доступа доступен на уровне корзин. В зависимости от объема данных и их характера, поиск данных в меньшей корзине с меньшим количеством данных будет быстрее.
Подробности об этих двух целях см. в следующих разделах.
Когда следует создавать пользовательские корзины и как предоставить к ним доступ?¶
Начните с обдумывания сроков хранения для каждого типа данных для ваших сценариев использования. Для устранения неполадок приложений может потребоваться только 14 дней логов, тогда как журналы аудита могут храниться несколько лет.
Мы рассмотрим логи как пример типа данных, но эти советы применимы и ко всем другим типам данных. Только метрики отличаются, и мы рассмотрим метрики позже.
Большая часть данных логов может потребоваться для устранения неполадок, и вы не хотите хранить эти массивные данные очень долго. Старайтесь хранить эти логи как можно короче. Это снижает затраты и ускоряет и удешевляет устранение неполадок. Обычно 14 дней может быть достаточно. Итак, как лучше это сделать?
- Создайте пользовательскую корзину.
Вы можете создать пользовательскую корзину через API управления хранилищем Grail или использовать приложение управления хранилищем Grail.
Для создания пользовательских корзин Grail вашей группе необходимо привязать политику со следующими утверждениями:
ALLOW storage:bucket-definitions:read,
storage:bucket-definitions:write,
storage:bucket-definitions:truncate,
storage:bucket-definitions:delete;
Мы назвали нашу первую пользовательскую корзину log_sec_dev_troubleshoot_14d.
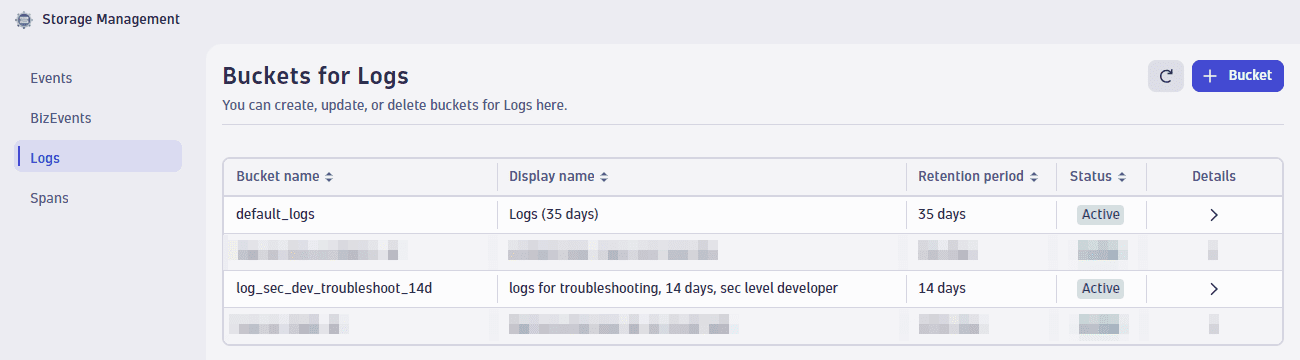 2. Отправьте данные.
2. Отправьте данные.
После создания корзины Grail пора загрузить данные. Вам нужно создать или настроить правило назначения корзины для логов для хранения логов устранения неполадок в этой новой корзине. У вас есть две возможности:
- Отправлять только определенные логи в новую корзину логов, добавив правила назначения корзин.
- Отправлять все логи по умолчанию в 14-дневную корзину и добавить правила назначения для других сроков хранения.
Давайте создадим новое правило по умолчанию для хранения всех логов только 14 дней, с одним исключением — хранение в корзине по умолчанию на 35 дней.
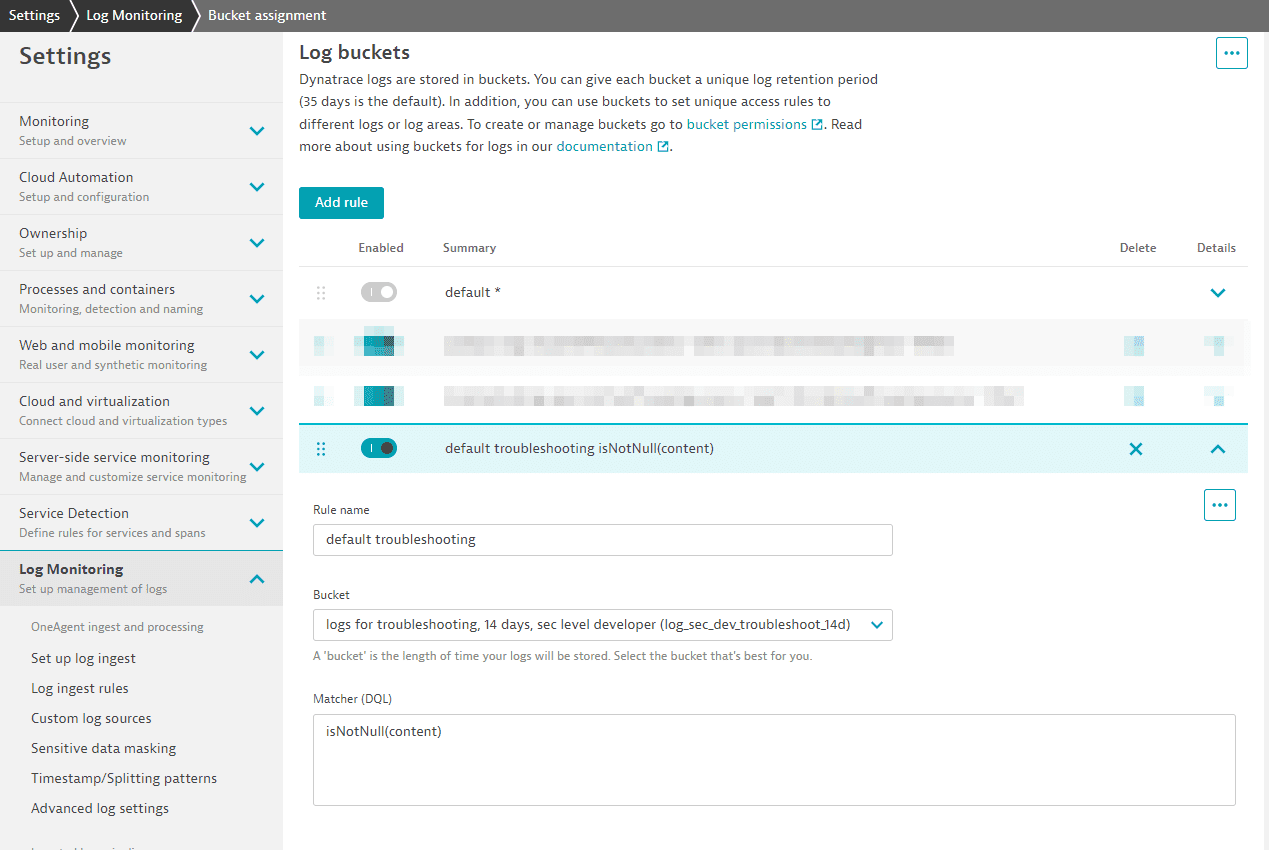
Сопоставитель для логов всегда будет равен true и, следовательно, будет соответствовать любой строке лога. Это будет улучшено в ближайшее время путем простого добавления «true» в сопоставитель. Это правило должно быть последним в списке. Это гарантирует, что каждая строка лога, не совпавшая ранее, будет храниться в корзине 14 дней.
Это второе правило хранит логи из приложения бронирования с термином b-app или http в источнике лога в нашей корзине логов по умолчанию на 35 дней:
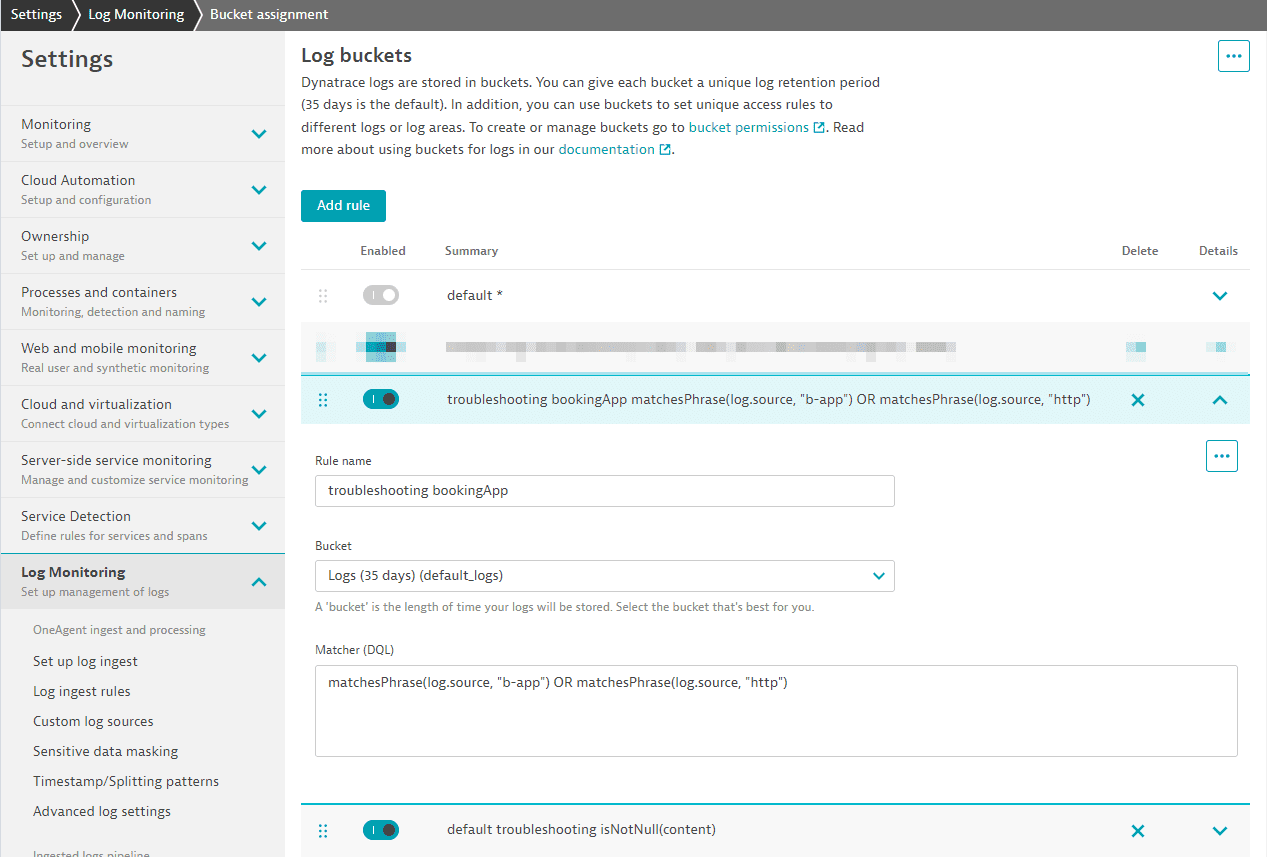
Примечание: старое правило по умолчанию больше не будет совпадать. Оно всегда выполняется последним и, поскольку у нас есть новое правило-перехватчик, оно больше не будет использоваться. 3. Создайте корзину с длительным хранением для аналитических данных.
Прежде чем мы закончим, нам нужна еще одна корзина для информации из логов, которую нужно хранить гораздо дольше для аналитических сценариев использования.
Этот лог содержит техническую информацию об использовании продукта в сочетании с технической информацией. Мы хотим хранить их в отдельной корзине с более длительным сроком хранения. Эту аналитическую корзину логов можно использовать для всех строк логов, необходимых для аналитических сценариев, если срок хранения одинаков.
Нам нужно повторить шаги и создать новую корзину логов и правило назначения корзины. Годовая корзина логов называется log_sec_dev_analytics_1y.
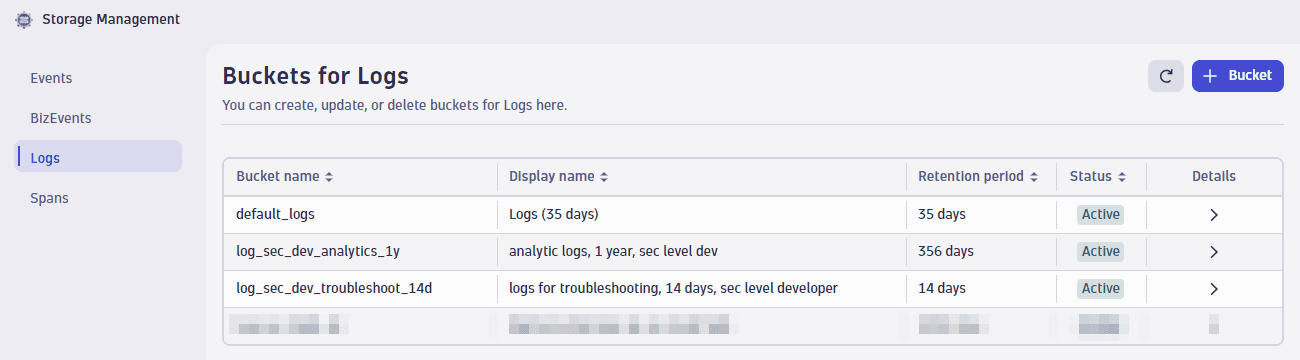
Аналитические строки логов можно легко идентифицировать, так как существует общекорпоративное соглашение о том, что все аналитические строки логов имеют уровень лога INFO и содержат термин app_analytics.
Мы добавляем правило назначения корзины со следующим сопоставителем:
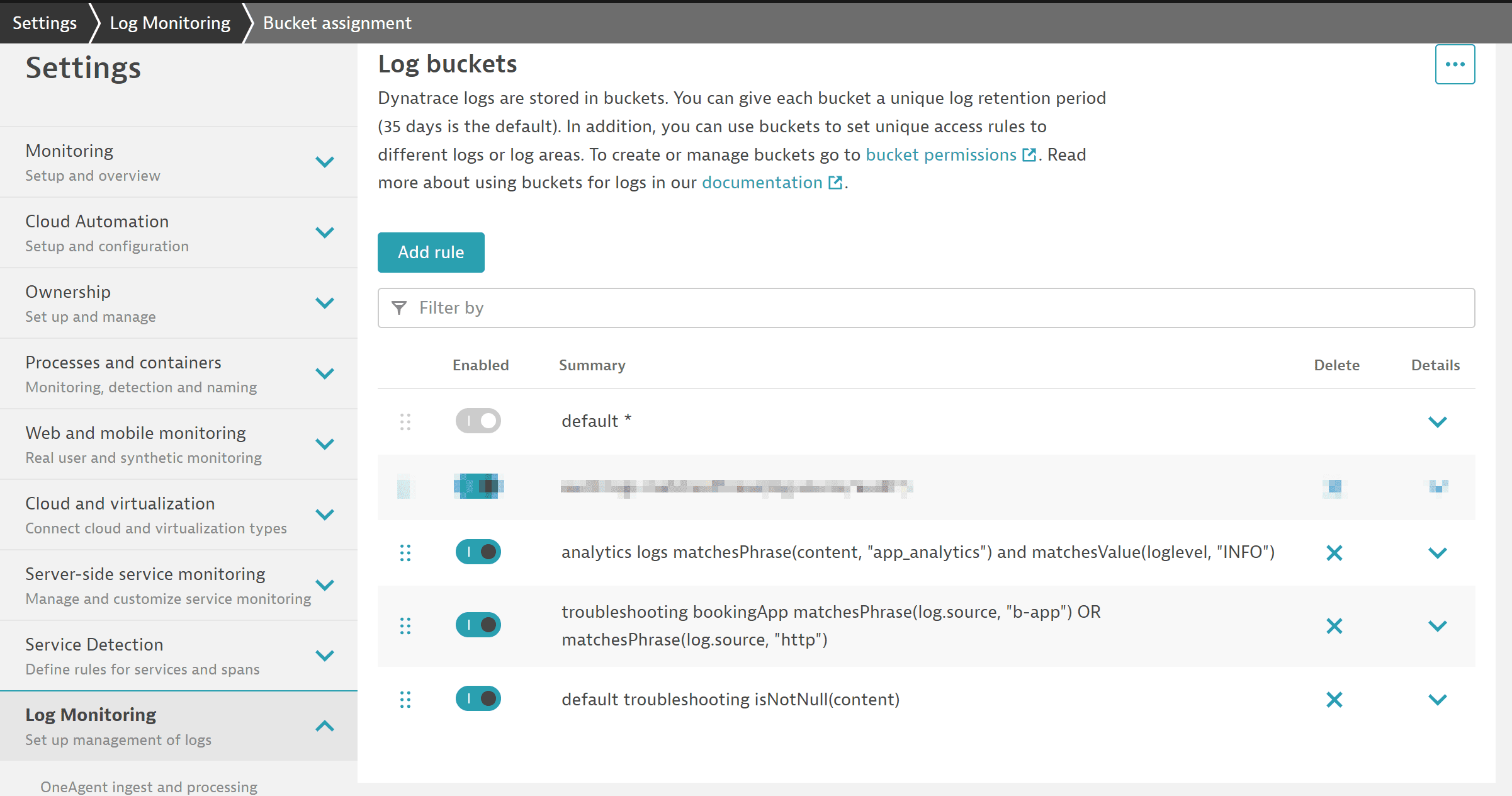
Файлы логов, хранящиеся в наших трех корзинах (две пользовательские корзины плюс корзина логов по умолчанию), доступны всем разработчикам, и нам нужно установить правильные разрешения для доступа к этим корзинам.
Вот необходимая политика:
ALLOW storage:buckets:read WHERE storage:bucket-name STARTSWITH "log_sec_dev";
ALLOW storage:buckets:read WHERE storage:bucket-name = "default_logs";
ALLOW storage:logs:read;
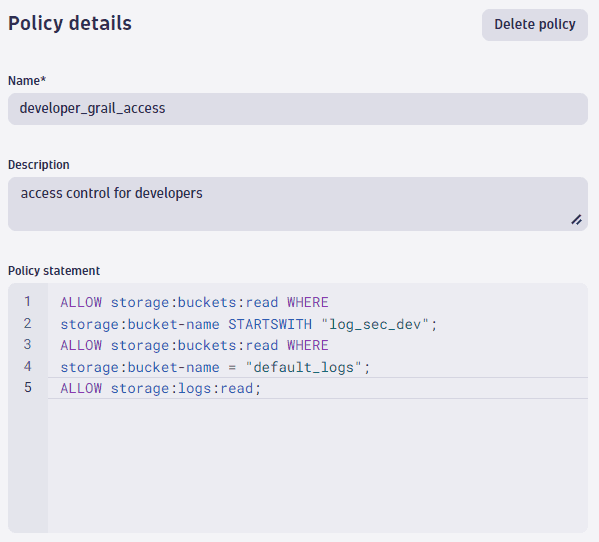
Если вы посмотрите на утверждение политики, вы увидите условие STARTSWITH. Шаблон именования, который мы использовали для наших корзин, начинается с типа данных log, за которым следует уровень безопасности, где sec_dev — для разработчиков. Таким образом можно сократить количество различных необходимых политик.
Предположим, у вас также есть данные событий, спанов и даже бизнес-событий, и вы разрешаете всем разработчикам доступ к этим данным. Удалив тип данных log_ из имени корзины, вы можете написать простую политику, разрешающую доступ ко всем корзинам, начинающимся с sec_dev.
Как бы вы поступили со строками логов, к которым должны иметь доступ только определенные лица, и вам нужно хранить их еще дольше? Типичным примером являются журналы доступа.
Снова создаем корзину на 3 года и сопоставитель логов для хранения этих конкретных логов в корзине, а также создаем политику для доступа к данным.
- Имя корзины:
log_sec_high_3y(sec_high— шаблон именования для высокого уровня безопасности) -
Правило назначения для наших журналов аудита:
3. Политика:
Сегментация данных¶
В чем разница между зонами управления и новыми сегментами?¶
Текущая концепция зон управления : Косвенно фильтрует данные мониторинга на основе идентификаторов сущностей предварительно рассчитанных зон управления.
Сегменты для структурирования данных в Grail : Сегментирует данные через повторно используемые условия фильтрации для анализа данных мониторинга в реальном времени.
После организации данных мониторинга в корзинах Grail и освоения настройки политик IAM, предоставляющих пользователям доступ к необходимым данным, последний шаг — понять, как данные мониторинга могут быть отфильтрованы в последней версии Dynatrace.
Сегменты во многом аналогичны зонам управления, поскольку позволяют абстрагировать сложные условия фильтрации и выполнять поиск по модели мониторируемых сущностей. Однако сегменты больше не являются предварительно рассчитанными атрибутами, а вместо этого являются условиями фильтрации во время выполнения запроса. Это решает проблему производительности зон управления, позволяя загружать и анализировать на несколько порядков больший объем данных мониторинга в последней версии Dynatrace.
Подробнее см. Сегменты.
Часто задаваемые вопросы¶
Когда мы храним данные в четырех корзинах, как это влияет на пользователей? Нужно ли им знать о корзинах?
Как описано в справочнике Модель данных Grail, корзины назначены таблицам. Поскольку наши четыре пользовательские корзины с данными логов назначены таблице логов, вы можете получить доступ ко всем данным в этой таблице через fetch logs. Пользователю не нужно выбирать корзину (или, как в других продуктах, индекс). Разработчики, конечно, получат данные только из корзин log_sec_dev_analytics_1y, log_sec_dev_troubleshoot_14d и default_logs, а не из log_sec_high_3y из-за наших определений политик.
Есть ли смысл фильтровать по корзине и как это можно сделать?
Да, это всегда хорошая практика — сузить данные, которые вы хотите анализировать или в которых ищете определенные термины.
Добавление фильтра по корзине — эффективный способ ускорить запрос и сократить объем сканируемых байтов. В зависимости от объема ваших данных это не всегда может быть заметно.
Для фильтрации наших логов устранения неполадок мы можем добавить этот критерий фильтрации:
Есть ли другие причины, по которым мне нужны разные корзины логов?
Grail создан для хранения и запросов данных с гиперскоростной обработкой данных. Если вы используете фильтры корзин для запросов данных, это ускорит запросы, но количество корзин ограничено до 80 на окружение.
Данные не могут быть перемещены между корзинами. Имейте это в виду, если:
- Есть причина физически разделить данные и обеспечить, чтобы стоимость запросов управлялась отдельно для разных подразделений/отделов.
- Ваша организация разделена на различные бизнес-подразделения с жесткими требованиями к управлению и наблюдению за использованием и стоимостью каждого выделенного бизнес-подразделения.
- Существуют разные этапы развертывания для крупной системы.
- Есть данные, которые нужно удалять вместе, или данные, где может потребоваться удалить определенные записи по запросу, например «Права субъекта данных».
Пример:
- Бизнес-подразделения A и B каждое предоставляют независимую ценность вашим клиентам/пользователям.
- Оба состоят из команд DevSecOps, а также чистых потребителей отчетов/дашбордов.
- Подразделения должны быть изолированы в плане доступа к данным и использования продукта и не должны видеть данные друг друга.
Чтобы гарантировать, что загрузка данных подразделения A не влияет на стоимость запросов или производительность подразделения B, настройте выделенные корзины для каждого бизнес-подразделения.
Не следует использовать корзины Grail для разделения данных по динамическим измерениям, например, создавая корзины для групп хостов или команд. Вы можете фильтровать данные по другим измерениям.
Если вам нужно ограничить доступ внутри корзин, вы можете использовать разрешения на уровне записей.
Есть ли способ ограничить доступ внутри корзин или даже таблиц?
Разрешения на уровне записей — это правильный способ реализации детального контроля доступа и дальнейшего ограничения доступа к данным. Вы можете использовать определенные выделенные поля, такие как event.kind или k8s.namespace.name, для создания политик, или добавить поле/измерение dt.security_context для контроля доступа по любым значениям, таким как названия команд.
Если вернуться к нашим примерам, мы определили политику, которая позволяет каждому разработчику получить доступ к логам, хранящимся в корзине по умолчанию и корзинах, начинающихся с шаблона именования: log_sec_dev.
Предположим, новая внешняя команда будет работать над проектом в течение следующих 18 месяцев, и вы хотите предоставить доступ только к логам, отмеченным их названием команды: extDev. Для этого убедитесь, что dt.security_context установлен в их логах, и создайте дополнительное утверждение:
ALLOW storage:buckets:read WHERE storage:bucket-name STARTSWITH "log_sec_dev";
ALLOW storage:buckets:read WHERE storage:bucket-name = "default_logs";
ALLOW storage:logs:read;
ALLOW storage:logs:read WHERE storage:dt.security_context=`"extDev";
Вы можете использовать OneAgentCtl для установки dt.security_context в качестве тега хоста на хостах, мониторируемых OneAgent:
Могу ли я использовать те же концепции для метрик?
Пользовательские корзины в настоящее время недоступны для метрик, но планируются. Сегодня метрики в Grail всегда хранятся в корзине по умолчанию с периодом хранения 15 месяцев. В будущем вы сможете увеличить 15 месяцев и использовать пользовательские корзины для метрик.
Разрешения на уровне записей также могут использоваться для метрик на поддерживаемых полях
или с использованием dt.security_context.
Что дальше?¶
После настройки окружения и его готовности для ваших команд начните изучать новый пользовательский интерфейс, приложения и узнайте, как обновить некоторые текущие возможности до новой платформы.
Пользовательский интерфейс Dynatrace¶
- Навигация по последней версии Dynatrace
- Новые визуализации данных
Приложения¶
 Dashboards
Dashboards  Notebooks
Notebooks  Workflows
Workflows  Kubernetes
Kubernetes  Site Reliability Guardian
Site Reliability Guardian ![]() Покрытие жизненного цикла DevSecOps с Snyk
Покрытие жизненного цикла DevSecOps с Snyk  Расследования
Расследования  Бизнес-процессы
Бизнес-процессы  Оптимизация затрат и углеродного следа
Оптимизация затрат и углеродного следа  Аналитика Salesforce
Аналитика Salesforce  Облака
Облака  Инфраструктура и операции
Инфраструктура и операции  Базы данных
Базы данных
Обновление¶
- Обновление классических дашбордов до Dashboards
- Обновление классического мониторинга логов до управления и аналитики логов
- Конвертация в DQL для логов
Дополнительные ресурсы¶
Ознакомьтесь со следующими дополнительными ресурсами, доступными на различных каналах самообслуживания Dynatrace.
Dynatrace University¶
Некоторые курсы по запросу, связанные с последней версией Dynatrace. Требуется авторизация.
Новости продукта¶
- Подключение пользователей к Grail и AppEngine
- Расширенное хранилище данных Grail и новый пользовательский интерфейс Dynatrace открывают безграничную аналитику
Начало работы с DQL¶
Начало работы с DQL
Дополнительные видео см. в плейлисте «Изучение языка запросов Dynatrace»
Что такое Dynatrace и как начать работу¶
Что такое Dynatrace и как начать работу
Дополнительные видео см. в плейлисте Dynatrace Observability Clinics
Тестовое окружение Dynatrace Playground¶
Перейдите в окружение Dynatrace Playground и получите практический опыт использования последней версии Dynatrace.