Оповещения о распространённых проблемах Kubernetes/OpenShift
Dynatrace версии 1.254+
ActiveGate версии 1.253+
Чтобы получать оповещения о распространённых проблемах платформы Kubernetes, следуйте приведённым ниже инструкциям.
Настройка¶
Существует три способа настройки оповещений о распространённых проблемах Kubernetes/OpenShift.
Настройка оповещения на другом уровне предназначена только для упрощения конфигурации нескольких сущностей одновременно. Это не меняет поведение оповещения.
Например, включение оповещения о насыщении использования CPU рабочей нагрузкой по-прежнему будет оценивать и создавать проблемы для каждой рабочей нагрузки Kubernetes отдельно, даже если оно было настроено на уровне кластера Kubernetes.
Подробнее об иерархии параметров см. в разделе Документация по параметрам.
На уровне тенанта
На уровне кластера
На уровне пространства имён
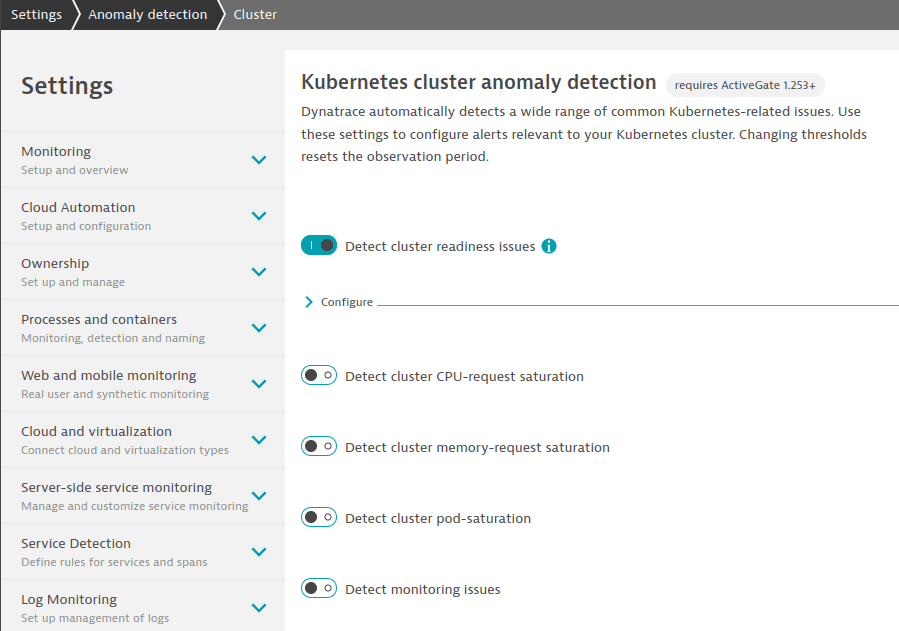
- Параметры применяются ко всем кластерам, узлам, пространствам имён или рабочим нагрузкам в тенанте Kubernetes/OpenShift.
- Для настройки параметров перейдите в Settings > Anomaly detection и выберите любую страницу в разделе Kubernetes.
Пример:
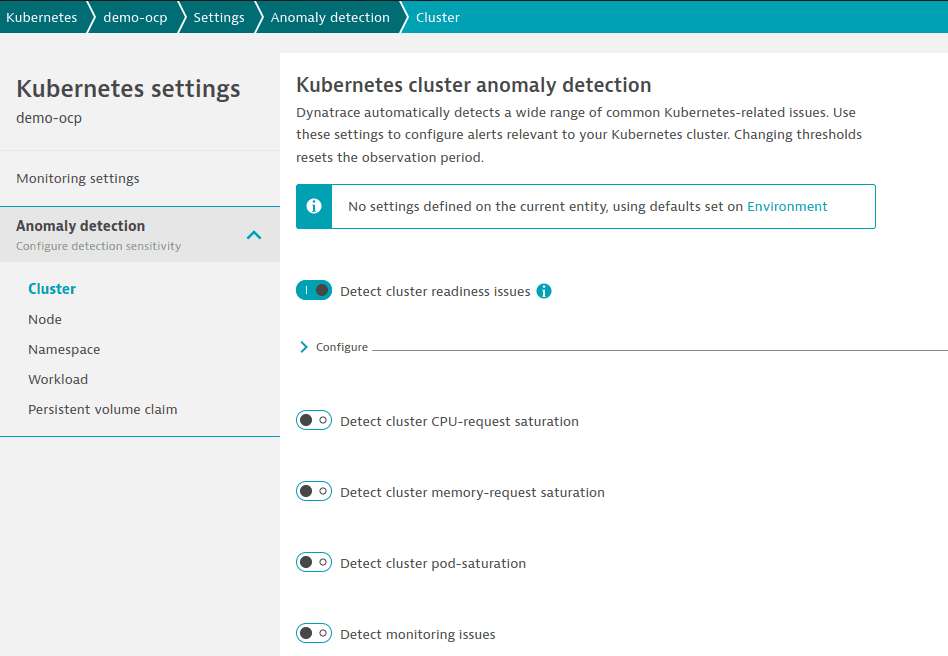
- Параметры применяются к выбранному кластеру или к узлам, пространствам имён и рабочим нагрузкам из выбранного кластера.
- Для настройки параметров перейдите в параметры выбранного кластера Kubernetes и выберите любую страницу в разделе Anomaly detection.
Пример:
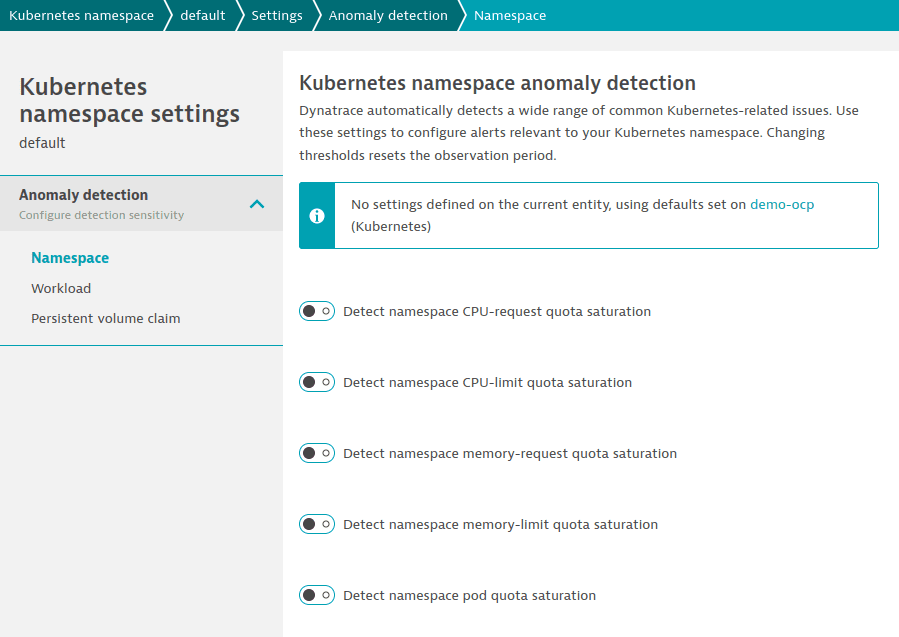
- Параметры применяются к выбранным пространствам имён или рабочим нагрузкам.
- Для настройки параметров перейдите в параметры выбранного пространства имён и выберите любую страницу в разделе Anomaly detection.
Пример:
Просмотр оповещений¶
Проблемы, закрытые вручную, появятся снова через 60 дней, если их первопричина остаётся неустранённой.
Оповещения можно просматривать:
- На странице Problems.
Пример проблемы:
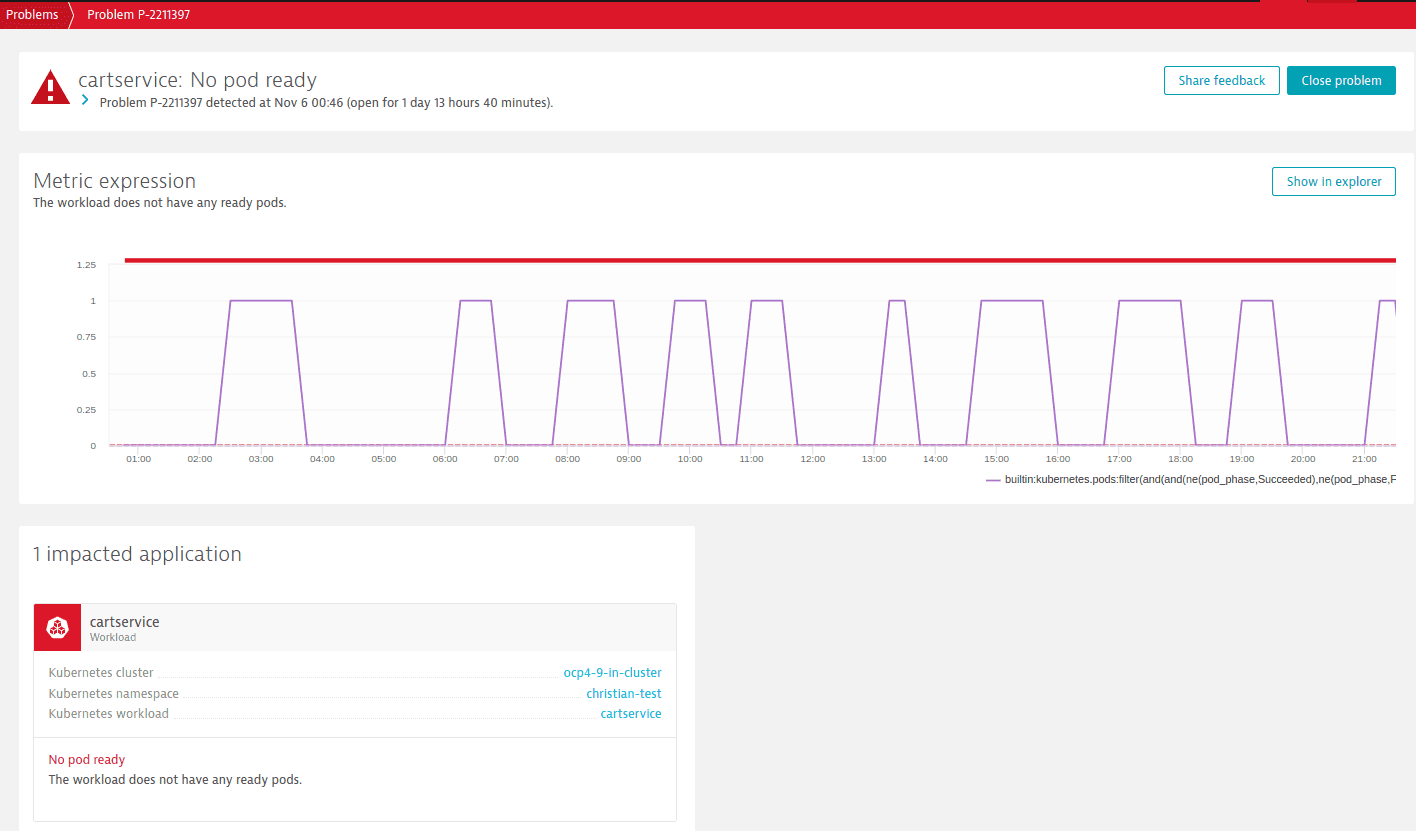 * В разделе Events страницы сведений о кластере.
* В разделе Events страницы сведений о кластере.
Пример события:
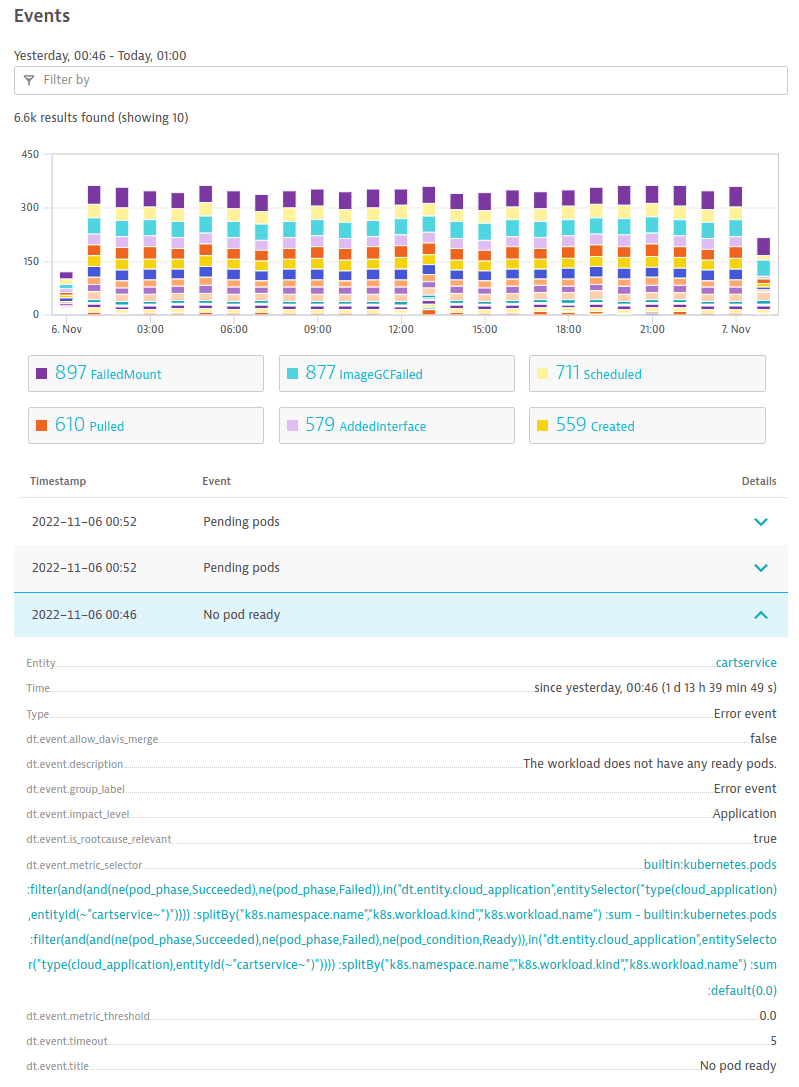
Выберите событие, чтобы перейти в Data Explorer для получения дополнительной информации о метрике, создавшей событие.
Доступные оповещения¶
Ниже приведён список доступных оповещений.
Оповещения для кластера¶
Метрика кластера и выражения DQL
Обнаружение насыщения запросов CPU в кластере¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.node.requests_cpu:splitBy():sum/builtin:kubernetes.node.cpu_allocatable:splitBy():sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.container.requests_cpu, rollup: avg), o2=sum(dt.kubernetes.node.cpu_allocatable, rollup: avg)}, by: {}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения запросов памяти в кластере¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.node.requests_memory:splitBy():sum/builtin:kubernetes.node.memory_allocatable:splitBy():sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.container.requests_memory, rollup: avg), o2=sum(dt.kubernetes.node.memory_allocatable, rollup: avg)}, by: {}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения подов в кластере¶
| Тип | Выражение |
|---|---|
| Выражение метрики | (builtin:kubernetes.node.pods:filter(and(eq(pod_condition,Ready))):splitBy():sum/builtin:kubernetes.node.pods_allocatable:splitBy():sum):default(0.0)*100.0 |
| DQL | timeseries o1=sum(dt.kubernetes.pods, rollup: avg), nonempty:true, filter: {((pod_condition=="Ready"))}, by: {}| join [timeseries operand=sum(dt.kubernetes.node.pods_allocatable, rollup: avg), nonempty:true, by: {}], on: {interval}, fields: {o2=operand}| fieldsAdd result=if(isNull(o1[]/o2[]), 0.0, else: o1[]/o2[])* 100.0| fieldsRemove {o1,o2} |
Обнаружение проблем готовности кластера¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.cluster.readyz:splitBy():sum |
| DQL | timeseries {sum(dt.kubernetes.cluster.readyz, rollup: avg)}, by: {} |
Обнаружение проблем мониторинга¶
| Тип | Выражение |
|---|---|
| Выражение метрики | (no metric expression) |
| DQL | (no DQL) |
Оповещения по умолчанию для новых тенантов
Оповещения для пространства имён¶
Метрика пространства имён и выражения DQL
Обнаружение насыщения квоты лимитов CPU пространства имён¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.resourcequota.limits_cpu_used:splitBy(k8s.namespace.name):sum/builtin:kubernetes.resourcequota.limits_cpu:splitBy(k8s.namespace.name):sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.resourcequota.limits_cpu_used, rollup: avg), o2=sum(dt.kubernetes.resourcequota.limits_cpu, rollup: avg)}, by: {k8s.namespace.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения квоты запросов CPU пространства имён¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.resourcequota.requests_cpu_used:splitBy(k8s.namespace.name):sum/builtin:kubernetes.resourcequota.requests_cpu:splitBy(k8s.namespace.name):sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.resourcequota.requests_cpu_used, rollup: avg), o2=sum(dt.kubernetes.resourcequota.requests_cpu, rollup: avg)}, by: {k8s.namespace.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения квоты лимитов памяти пространства имён¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.resourcequota.limits_memory_used:splitBy(k8s.namespace.name):sum/builtin:kubernetes.resourcequota.limits_memory:splitBy(k8s.namespace.name):sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.resourcequota.limits_memory_used, rollup: avg), o2=sum(dt.kubernetes.resourcequota.limits_memory, rollup: avg)}, by: {k8s.namespace.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения квоты запросов памяти пространства имён¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.resourcequota.requests_memory_used:splitBy(k8s.namespace.name):sum/builtin:kubernetes.resourcequota.requests_memory:splitBy(k8s.namespace.name):sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.resourcequota.requests_memory_used, rollup: avg), o2=sum(dt.kubernetes.resourcequota.requests_memory, rollup: avg)}, by: {k8s.namespace.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения квоты подов пространства имён¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.resourcequota.pods_used:splitBy(k8s.namespace.name):sum/builtin:kubernetes.resourcequota.pods:splitBy(k8s.namespace.name):sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.resourcequota.pods_used, rollup: avg), o2=sum(dt.kubernetes.resourcequota.pods, rollup: avg)}, by: {k8s.namespace.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Оповещения для узла¶
Метрика узла и выражения DQL
Обнаружение насыщения запросов CPU узла¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.node.requests_cpu:splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum/builtin:kubernetes.node.cpu_allocatable:splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.container.requests_cpu, rollup: avg), o2=sum(dt.kubernetes.node.cpu_allocatable, rollup: avg)}, by: {dt.kubernetes.node.system_uuid,k8s.node.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения запросов памяти узла¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.node.requests_memory:splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum/builtin:kubernetes.node.memory_allocatable:splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.container.requests_memory, rollup: avg), o2=sum(dt.kubernetes.node.memory_allocatable, rollup: avg)}, by: {dt.kubernetes.node.system_uuid,k8s.node.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение насыщения подов узла¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.node.pods:filter(and(eq(pod_phase,Running))):splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum/builtin:kubernetes.node.pods_allocatable:splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum*100.0 |
| DQL | timeseries o1=sum(dt.kubernetes.pods, rollup: avg), nonempty:true, filter: {((pod_phase=="Running"))}, by: {dt.kubernetes.node.system_uuid,k8s.node.name}| join [timeseries operand=sum(dt.kubernetes.node.pods_allocatable, rollup: avg), nonempty:true, by: {dt.kubernetes.node.system_uuid,k8s.node.name}], on: {interval}, fields: {o2=operand}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение проблем готовности узла¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.node.conditions:filter(and(eq(node_condition,Ready),ne(condition_status,True))):splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum |
| DQL | timeseries {sum(dt.kubernetes.node.conditions, rollup: avg)}, filter: {((node_condition=="Ready")AND(condition_status!=true))}, by: {dt.kubernetes.node.system_uuid,k8s.node.name} |
Обнаружение проблемных состояний узла¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.node.conditions:filter(and(or(eq(node_condition,ContainerRuntimeProblem),eq(node_condition,ContainerRuntimeUnhealthy),eq(node_condition,CorruptDockerOverlay2),eq(node_condition,DiskPressure),eq(node_condition,FilesystemCorruptionProblem),eq(node_condition,FrequentContainerdRestart),eq(node_condition,FrequentDockerRestart),eq(node_condition,FrequentGcfsSnapshotterRestart),eq(node_condition,FrequentGcfsdRestart),eq(node_condition,FrequentKubeletRestart),eq(node_condition,FrequentUnregisterNetDevice),eq(node_condition,GcfsSnapshotterMissingLayer),eq(node_condition,GcfsSnapshotterUnhealthy),eq(node_condition,GcfsdUnhealthy),eq(node_condition,KernelDeadlock),eq(node_condition,KubeletProblem),eq(node_condition,KubeletUnhealthy),eq(node_condition,MemoryPressure),eq(node_condition,NetworkUnavailable),eq(node_condition,OutOfDisk),eq(node_condition,PIDPressure),eq(node_condition,ReadonlyFilesystem)),eq(condition_status,True))):splitBy(dt.kubernetes.node.system_uuid,k8s.node.name):sum |
| DQL | timeseries {sum(dt.kubernetes.node.conditions, rollup: avg)}, filter: {(((node_condition=="ContainerRuntimeProblem")OR(node_condition=="ContainerRuntimeUnhealthy")OR(node_condition=="CorruptDockerOverlay2")OR(node_condition=="DiskPressure")OR(node_condition=="FilesystemCorruptionProblem")OR(node_condition=="FrequentContainerdRestart")OR(node_condition=="FrequentDockerRestart")OR(node_condition=="FrequentGcfsSnapshotterRestart")OR(node_condition=="FrequentGcfsdRestart")OR(node_condition=="FrequentKubeletRestart")OR(node_condition=="FrequentUnregisterNetDevice")OR(node_condition=="GcfsSnapshotterMissingLayer")OR(node_condition=="GcfsSnapshotterUnhealthy")OR(node_condition=="GcfsdUnhealthy")OR(node_condition=="KernelDeadlock")OR(node_condition=="KubeletProblem")OR(node_condition=="KubeletUnhealthy")OR(node_condition=="MemoryPressure")OR(node_condition=="NetworkUnavailable")OR(node_condition=="OutOfDisk")OR(node_condition=="PIDPressure")OR(node_condition=="ReadonlyFilesystem"))AND(condition_status==true))}, by: {dt.kubernetes.node.system_uuid,k8s.node.name} |
Оповещения по умолчанию для новых тенантов
Оповещения для заявок на постоянные тома¶
Метрика заявок на постоянные тома и выражения DQL
Обнаружение нехватки дискового пространства (%)¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.persistentvolumeclaim.available:splitBy(k8s.namespace.name,k8s.persistent_volume_claim.name):avg/builtin:kubernetes.persistentvolumeclaim.capacity:splitBy(k8s.namespace.name,k8s.persistent_volume_claim.name):avg*100.0 |
| DQL | timeseries {o1=avg(dt.kubernetes.persistentvolumeclaim.available), o2=avg(dt.kubernetes.persistentvolumeclaim.capacity)}, by: {k8s.namespace.name,k8s.persistent_volume_claim.name}| fieldsAdd result=o1[]/o2[]* 100.0| fieldsRemove {o1,o2} |
Обнаружение нехватки дискового пространства (МиБ)¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.persistentvolumeclaim.available:splitBy(k8s.namespace.name,k8s.persistent_volume_claim.name):avg |
| DQL | timeseries {avg(dt.kubernetes.persistentvolumeclaim.available)}, by: {k8s.namespace.name,k8s.persistent_volume_claim.name} |
Оповещения для рабочей нагрузки¶
Метрика рабочей нагрузки и выражения DQL
Обнаружение насыщения использования CPU¶
| Тип | Выражение |
|---|---|
| Выражение метрики | (builtin:kubernetes.workload.cpu_usage:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum/builtin:kubernetes.workload.limits_cpu:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum):default(0.0)*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.container.cpu_usage, rollup: avg), o2=sum(dt.kubernetes.container.limits_cpu, rollup: avg)}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name}| fieldsAdd result=if(isNull(o1[]/o2[]), 0.0, else: o1[]/o2[])* 100.0| fieldsRemove {o1,o2} |
Обнаружение перезапусков контейнеров¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.container.restarts:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries {sum(dt.kubernetes.container.restarts, default:0.0, rollup: avg)}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение высокого ограничения CPU¶
| Тип | Выражение |
|---|---|
| Выражение метрики | (builtin:kubernetes.workload.cpu_throttled:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum/builtin:kubernetes.workload.limits_cpu:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum):default(0.0)*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.container.cpu_throttled, rollup: avg), o2=sum(dt.kubernetes.container.limits_cpu, rollup: avg)}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name}| fieldsAdd result=if(isNull(o1[]/o2[]), 0.0, else: o1[]/o2[])* 100.0| fieldsRemove {o1,o2} |
Обнаружение событий сбоя задания¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.events:filter(and(or(eq(k8s.event.reason,BackoffLimitExceeded),eq(k8s.event.reason,DeadlineExceeded),eq(k8s.event.reason,PodFailurePolicy)),or(eq(k8s.workload.kind,job),eq(k8s.workload.kind,cronjob)))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries {sum(dt.kubernetes.events, default:0.0, rollup: avg)}, filter: {(((k8s.event.reason=="BackoffLimitExceeded")OR(k8s.event.reason=="DeadlineExceeded")OR(k8s.event.reason=="PodFailurePolicy"))AND((k8s.workload.kind=="job")OR(k8s.workload.kind=="cronjob")))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение насыщения использования памяти¶
| Тип | Выражение |
|---|---|
| Выражение метрики | (builtin:kubernetes.workload.memory_working_set:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum/builtin:kubernetes.workload.limits_memory:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum):default(0.0)*100.0 |
| DQL | timeseries {o1=sum(dt.kubernetes.container.memory_working_set, rollup: avg), o2=sum(dt.kubernetes.container.limits_memory, rollup: avg)}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name}| fieldsAdd result=if(isNull(o1[]/o2[]), 0.0, else: o1[]/o2[])* 100.0| fieldsRemove {o1,o2} |
Обнаружение завершений по исчерпанию памяти (OOM)¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.container.oom_kills:splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries {sum(dt.kubernetes.container.oom_kills, default:0.0, rollup: avg)}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение событий откатов подов¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.events:filter(and(eq(k8s.event.reason,BackOff))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries {sum(dt.kubernetes.events, default:0.0, rollup: avg)}, filter: {((k8s.event.reason=="BackOff"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение событий вытеснения подов¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.events:filter(and(eq(k8s.event.reason,Evicted))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries {sum(dt.kubernetes.events, default:0.0, rollup: avg)}, filter: {((k8s.event.reason=="Evicted"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение событий вытеснения с приоритетом¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.events:filter(or(eq(k8s.event.reason,Preempted),eq(k8s.event.reason,Preempting))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries {sum(dt.kubernetes.events, default:0.0, rollup: avg)}, filter: {((k8s.event.reason=="Preempted")OR(k8s.event.reason=="Preempting"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение подов, зависших в состоянии ожидания¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.pods:filter(and(eq(pod_phase,Pending))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum |
| DQL | timeseries {sum(dt.kubernetes.pods, rollup: avg)}, filter: {((pod_phase=="Pending"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение подов, зависших в состоянии завершения¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.pods:filter(and(eq(pod_status,Terminating))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum |
| DQL | timeseries {sum(dt.kubernetes.pods, rollup: avg)}, filter: {((pod_status=="Terminating"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение зависших развёртываний¶
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.workload.conditions:filter(and(eq(workload_condition,Progressing),eq(condition_status,False))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum |
| DQL | timeseries {sum(dt.kubernetes.workload.conditions, rollup: avg)}, filter: {((workload_condition=="Progressing")AND(condition_status==false))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name} |
Обнаружение рабочих нагрузок с неготовыми подами¶
Следующее выражение возвращает количество ожидающих и выполняющихся подов в состоянии неготовности. Поды Jobs и CronJobs исключены.
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.pods:filter(and(ne(pod_phase,Failed),ne(pod_phase,Succeeded),ne(k8s.workload.kind,job),ne(k8s.workload.kind,cronjob),ne(pod_status,Terminating))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum-builtin:kubernetes.pods:filter(and(ne(pod_phase,Failed),ne(pod_phase,Succeeded),ne(k8s.workload.kind,job),ne(k8s.workload.kind,cronjob),eq(pod_condition,Ready),ne(pod_status,Terminating))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries o1=sum(dt.kubernetes.pods, rollup: avg), filter: {((pod_phase!="Failed")AND(pod_phase!="Succeeded")AND(k8s.workload.kind!="job")AND(k8s.workload.kind!="cronjob")AND(pod_status!="Terminating"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name}| join [timeseries operand=sum(dt.kubernetes.pods, default:0.0, rollup: avg), nonempty:true, filter: {((pod_phase!="Failed")AND(pod_phase!="Succeeded")AND(k8s.workload.kind!="job")AND(k8s.workload.kind!="cronjob")AND(pod_condition=="Ready")AND(pod_status!="Terminating"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name}], on: {interval}, fields: {o2=operand}| fieldsAdd result=o1[]-o2[]| fieldsRemove {o1,o2} |
Обнаружение рабочих нагрузок без готовых подов¶
Следующее выражение возвращает количество ожидающих и выполняющихся подов в состоянии готовности. Поды Jobs и CronJobs исключены.
| Тип | Выражение |
|---|---|
| Выражение метрики | builtin:kubernetes.pods:filter(and(ne(pod_phase,Failed),ne(pod_phase,Succeeded),ne(k8s.workload.kind,job),ne(k8s.workload.kind,cronjob))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum-builtin:kubernetes.pods:filter(and(ne(pod_phase,Failed),ne(pod_phase,Succeeded),ne(k8s.workload.kind,job),ne(k8s.workload.kind,cronjob),ne(pod_condition,Ready))):splitBy(k8s.namespace.name,k8s.workload.kind,k8s.workload.name):sum:default(0.0) |
| DQL | timeseries o1=sum(dt.kubernetes.pods, rollup: avg), filter: {((pod_phase!="Failed")AND(pod_phase!="Succeeded")AND(k8s.workload.kind!="job")AND(k8s.workload.kind!="cronjob"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name}| join [timeseries operand=sum(dt.kubernetes.pods, default:0.0, rollup: avg), nonempty:true, filter: {((pod_phase!="Failed")AND(pod_phase!="Succeeded")AND(k8s.workload.kind!="job")AND(k8s.workload.kind!="cronjob")AND(pod_condition!="Ready"))}, by: {k8s.namespace.name,k8s.workload.kind,k8s.workload.name}], on: {interval}, fields: {o2=operand}| fieldsAdd result=o1[]-o2[]| fieldsRemove {o1,o2} |
Оповещения по умолчанию для новых тенантов¶
Связанные темы¶
- Настройка Dynatrace в Kubernetes