Использование трассировок, DQL и логов для выявления закономерностей
Выявляйте аномальные закономерности в трассировках и логах с помощью  Distributed Tracing и Dynatrace Query Language (DQL).
Distributed Tracing и Dynatrace Query Language (DQL).
Введение¶
В этом руководстве вы узнаете, как использовать трассировки, DQL и логи для:
- Выявления неэффективных запросов к базе данных.
- Понимания закономерностей рабочей нагрузки.
- Обнаружения аномалий в использовании базы данных.
- Анализа производительности.
- Понимания влияния отдельных запросов к базе данных (например, сколько данных они изменяют).
Для удобства разделы, в которых используется Distributed Tracing, отмечены значком , а разделы, в которых используется DQL, отмечены значком . Кроме того, для подробного объяснения каждого DQL-запроса выберите Пояснение к DQL-запросу над блоком кода DQL-запроса.
Целевая аудитория¶
Любой пользователь последней версии Dynatrace, который хочет больше узнать о трассировках, логах и DQL, а также понять, как эффективно их использовать.
Результат обучения¶
После прохождения этого руководства вы научитесь составлять и эффективно использовать различные DQL-запросы, которые помогут вам оптимизировать устранение неполадок, настроить оповещения и автоматизировать рабочие процессы.
Прежде чем начать¶
Предварительные требования¶
Для прохождения этого руководства вам нужен только доступ к последней версии Dynatrace в вашей среде.
Также вы можете использовать нашу среду Dynatrace Playground для выполнения шагов этого руководства.
Необходимые знания¶
- Знакомство с последней версией Dynatrace
- Хотя бы базовые знания DQL
- Понимание того, что такое Distributed Tracing
Для обзора посмотрите видео Unleash the Power of Distributed Tracing на YouTube.
Выявление неэффективных паттернов запросов к базе данных¶
Независимо от того, выполняется ли определённый SQL-оператор повторно, вызываются ли несколько различных SQL-операторов в рамках трассировки или задействован один длительный запрос — каждый из этих сценариев представляет собой потенциальную проблему производительности, которую мы стремимся обнаружить.
Distributed Tracing Обнаружение паттернов запросов с помощью Distributed Tracing¶
Начнём с Distributed Tracing. Благодаря этому приложению мы можем быстро выявлять неэффективное или избыточное использование базы данных с помощью нескольких фильтров, группировок и представлений.
- Перейдите в Distributed Tracing.
- В верхней левой части страницы, под заголовком приложения, выберите Spans, чтобы просмотреть анализ на основе спанов запросов.
- В текстовом поле Search facets введите Databases и выберите фасет Databases, чтобы отобразить все связанные метаданные.
- Рядом с Db query text выберите (More) > Group by, чтобы мгновенно проанализировать все запросы к базе данных по спанам.
В этом представлении вы можете:
- Сортировать данные по различным параметрам в порядке возрастания или убывания.
- Группировать данные по нескольким атрибутам.
- Сужать выборку данных с помощью различных фильтров.
Вы можете применять описанные ниже техники к исключениям, хостам, процессам, удалённым вызовам процедур и многому другому.
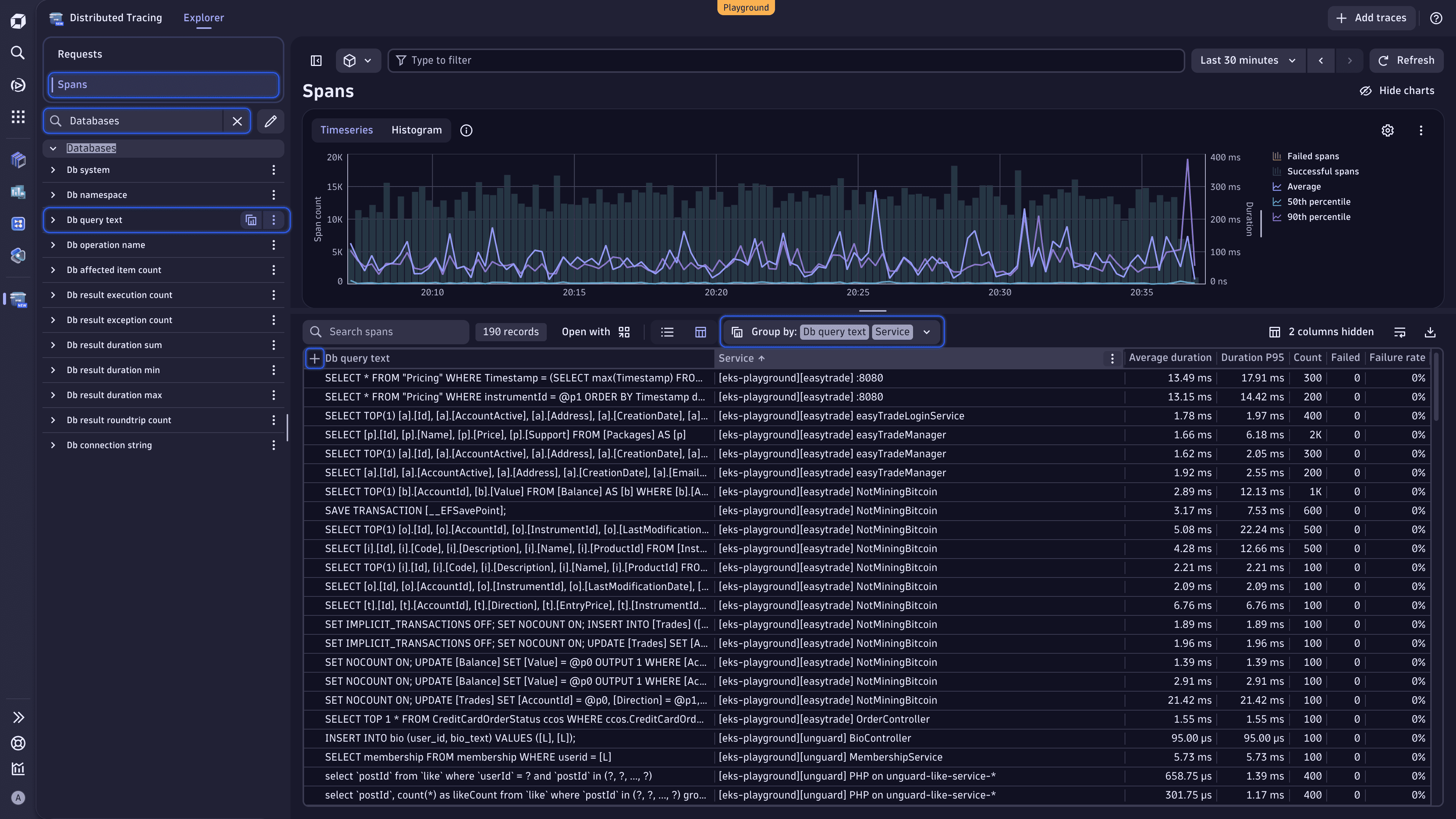
Сортировка данных¶
Выберите заголовки столбцов таблицы, чтобы отсортировать данные по различным параметрам и выявить определённые паттерны запросов к базе данных.
- Count: Найти наиболее частые запросы.
- Average duration: Обнаружить самые длительные запросы.
- Failure rate: Просмотреть запросы к базе данных с наибольшей частотой ошибок.
Группировка данных по нескольким атрибутам¶
Разделяйте данные по нескольким атрибутам для уточнения представления.
- Прямо над таблицей раскройте выпадающий список Group by и выберите Services. У вас должна получиться следующая группировка: Group by: Db query text | Service.
Таким образом, вы сможете увидеть, какие запросы к базе данных являются общими для разных сервисов. 2. Измените порядок атрибутов группировки. В выпадающем списке Group by снимите выбор с Db query text, а затем выберите этот атрибут снова. У вас должна получиться следующая группировка: Group by: Service | Db query text.
В этом случае вы можете увидеть, какие запросы к базе данных выполняет каждый сервис. 3. Выберите слева от текущего активного первичного атрибута, чтобы развернуть атрибут и просмотреть запрошенный анализ.
Порядок, в котором вы размещаете атрибуты группировки, напрямую влияет на получаемые результаты.
Сужение данных с помощью фильтров¶
Применяйте фильтры для сужения выборки данных.
В текстовом поле Type to filter введите запрос. Например, введите "Db query text" = *, чтобы исключить спаны с пустыми запросами к базе данных.
Обнаружение необычных паттернов с помощью DQL¶
После использования Distributed Tracing давайте узнаем, как использовать DQL для выявления нетипичных паттернов в трассировках и логах. Мы рекомендуем использовать  Notebooks для выполнения всех примеров DQL-запросов в этом руководстве.
Notebooks для выполнения всех примеров DQL-запросов в этом руководстве.
- Перейдите в Notebooks.
- Выберите Notebook в заголовке приложения, чтобы создать новый ноутбук.
- Откройте меню Add и выберите DQL.
Вы можете добавить несколько DQL-секций для всех DQL-запросов, представленных в руководстве. 4. В секции запроса введите DQL-запрос. 5. Выберите Run, чтобы выполнить DQL-запрос.
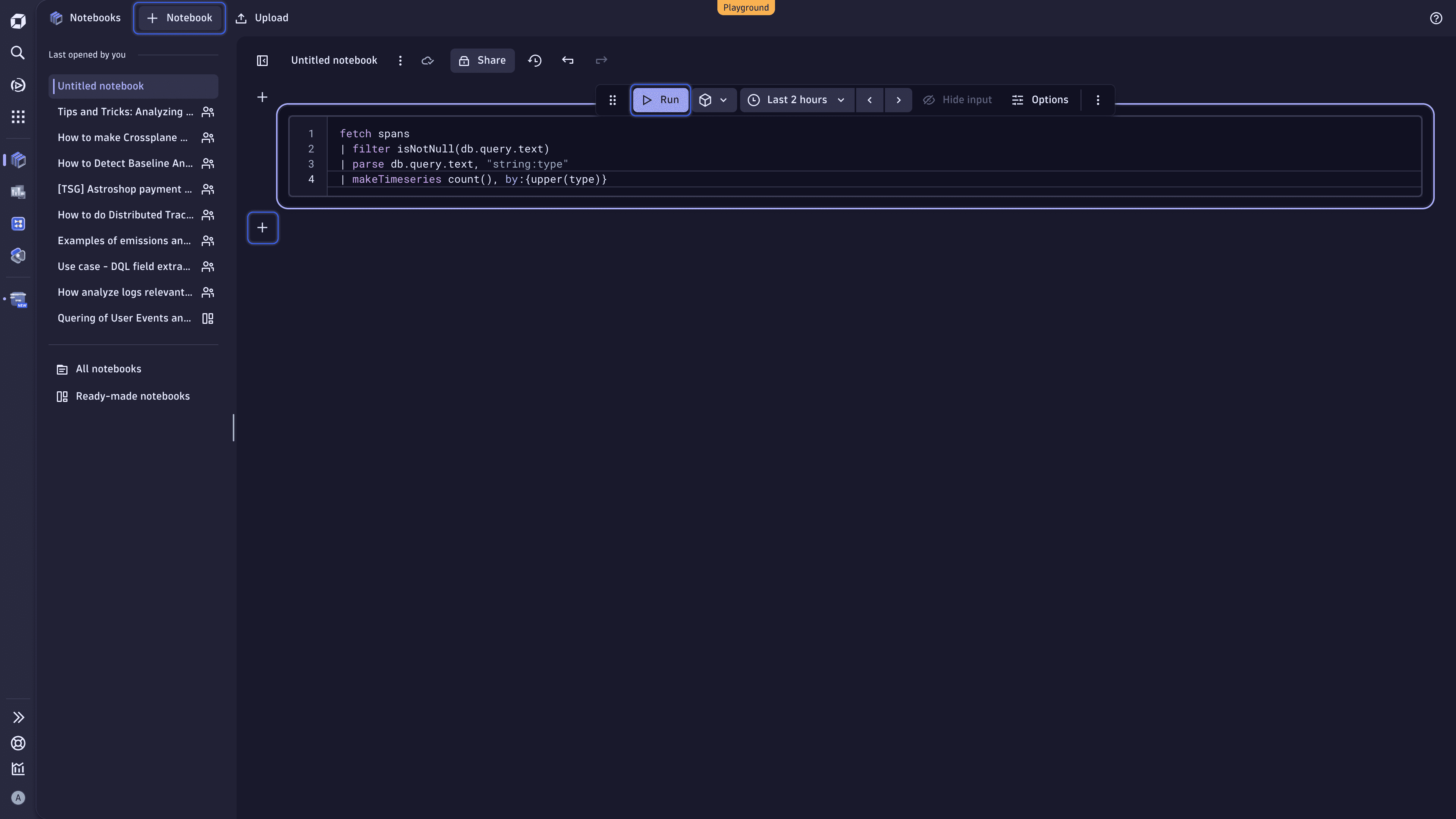
Обнаружение наиболее частых типов запросов¶
Давайте проверим, как часто определённый тип запроса (например, INSERT, SELECT или UPDATE) встречается в ваших спанах с течением времени. Скопируйте следующий запрос в секцию запроса ноутбука, а затем выберите Run, чтобы выполнить DQL-запрос.
Пояснение к DQL-запросу
fetch spans: Извлечение данных из таблицыspans, содержащей информацию об отдельных спанах.filter isNotNull(db.query.text): Включение только тех спанов, в которых присутствует запрос к базе данных.parse db.query.text, "string:type": Разбор поляdb.query.textи извлечение значенияtypeдля определения типа запроса. Это значение сохраняется в новом полеtype.makeTimeseries count(), by:{upper(type)}: Подсчёт количества появлений каждого типа запроса в спанах и создание временного ряда для визуализации.
fetch spans
| filter isNotNull(db.query.text)
| parse db.query.text, "string:type"
| makeTimeseries count(), by:{upper(type)}
Запустить в Playground
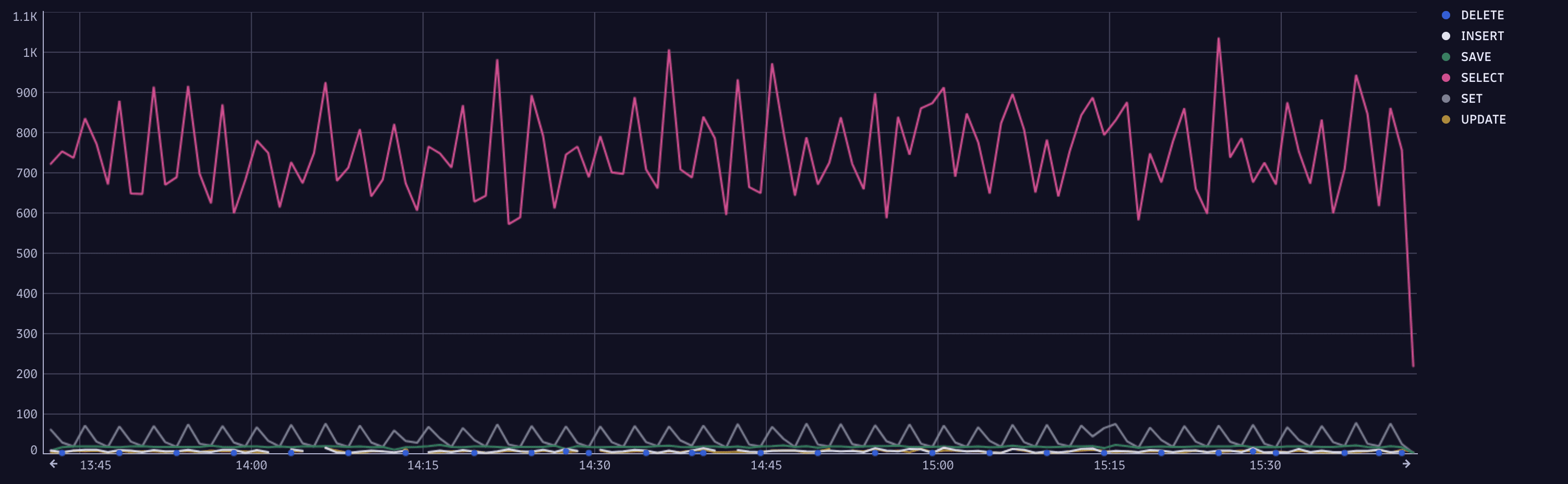
Используйте этот запрос для понимания закономерностей рабочей нагрузки или обнаружения аномалий.
Обнаружение ресурсоёмких запросов¶
Теперь выполним запрос ниже, чтобы увидеть, сколько времени занимают ваши запросы к базе данных, и найти самые медленные запросы.
Пояснение к DQL-запросу
fetch spans: Извлечение данных из таблицыspans, содержащей информацию об отдельных спанах.filter isNotNull(db.query.text): Включение только тех спанов, в которых присутствует запрос к базе данных.makeTimeseries sum(duration), by:{db.query.text}: Создание временного ряда, показывающего сумму длительности каждого запроса, отсортированную по тексту запроса.
Запустить в Playground

Этот временной ряд позволяет обнаружить ресурсоёмкие запросы к базе данных и отлично подходит для настройки производительности. Когда запрос занимает слишком много времени, возможно, существует более эффективный запрос, достигающий той же цели.
Выявление запросов с высоким воздействием¶
С помощью этого запроса мы можем проверить, сколько строк данных затронуто — например, SELECT, INSERT или DELETE — каждым запросом к базе данных.
Пояснение к DQL-запросу
fetch spans: Извлечение данных из таблицыspans, содержащей информацию об отдельных спанах.filter isNotNull(db.query.text): Включение только тех спанов, в которых присутствует запрос к базе данных.makeTimeseries sum(db.affected_item_count), by:{db.query.text}: Создание временного ряда с суммированием количества затронутых строк данных, отсортированного по тексту запроса.
fetch spans
| filter isNotNull(db.query.text)
| makeTimeseries sum(db.affected_item_count), by:{db.query.text}
Запустить в Playground

Этот временной ряд показывает, сколько строк данных затронуто каждым запросом. Если определённый запрос затрагивает больше строк данных, чем другие, такой запрос является отличным кандидатом для оптимизации.
Обнаружение паттернов исключений¶
В этом разделе мы будем использовать DQL для выявления определённых паттернов исключений. Мы определим, какие типы исключений наиболее распространены, и найдём сервисы с наибольшим количеством исключений.
Подсчёт исключений по типу исключения¶
Мы сосредоточимся на количестве поступающих исключений и узнаем, как часто возникает каждый тип исключения.
Пояснение к DQL-запросу
fetch spans: Извлечение данных из таблицыspans, содержащей информацию об отдельных спанах.filter iAny(span.events[][span_event.name] == "exception"): Включение только тех спанов, которые содержат исключение.expand span.events: Развёртывание массиваspan.eventsдля работы с отдельными событиями спана вместо всего массива.fieldsFlatten span.events, fields: {exception.type}: Извлечение поляexception.typeиз каждого события спана и его развёртывание в отдельный столбец, по которому можно группировать и считать.makeTimeseries count(), by: {exception.type}, time:start_time: Создание временного ряда, показывающего количество исключений, сгруппированных по типу с течением времени. Этот временной ряд показывает, как часто возникает каждый тип исключения на основе времени начала спана.
fetch spans
| filter iAny(span.events[][span_event.name] == "exception")
| expand span.events
| fieldsFlatten span.events, fields: {exception.type}
| makeTimeseries count(), by: {exception.type}, time:start_time
Запустить в Playground

Проверка количества исключений по типу может быть полезна для мониторинга ошибок и отладки. С помощью этого запроса вы можете:
- Определить, какие типы исключений наиболее распространены.
- Обнаружить тренды или всплески определённых типов исключений.
- Соотнести частоту исключений с развёртываниями, изменениями трафика или другими системными событиями.
Обнаружение сервисов с наибольшим количеством исключений¶
С помощью следующего запроса мы получаем список сервисов с наибольшим количеством исключений.
Пояснение к DQL-запросу
fetch spans: Извлечение данных из таблицыspans, содержащей информацию об отдельных спанах.filter iAny(span.events[][span_event.name] == "exception"): Включение только тех спанов, которые содержат исключение.expand span.events: Развёртывание массиваspan.eventsдля работы с отдельными событиями спана вместо всего массива.fieldsFlatten span.events, fields: {exception.type, exception.message}: Развёртывание полейexception.typeиexception.message.summarize count(), by: {service.name, exception.message}: Суммирование этих полей по количеству и группировка по имени сервиса и сообщению исключения.
fetch spans
| filter iAny(span.events[][span_event.name] == "exception")
| expand span.events
| fieldsFlatten span.events, fields: {exception.type, exception.message}
| summarize count(), by: {service.name, exception.message}
Запустить в Playground
Обнаружение сервисов с наибольшим количеством исключений поможет вам расставить приоритеты в усилиях команды по устранению неполадок. Кроме того, знание наиболее распространённых сообщений исключений поможет обнаружить повторяющиеся ошибки или неправильные конфигурации.
Обнаружение «горячих» внутренних методов¶
Когда речь идёт об оптимизации кода, вы, возможно, захотите сначала увидеть, какие методы являются «горячими точками». В этом случае мы можем проанализировать все спаны, представляющие вызовы внутренних методов, и затем сгруппировать их по сервису и имени спана.
Distributed Tracing Поиск длительных спанов с помощью Distributed Tracing¶
Вот как мы достигаем этого в Distributed Tracing.
- Перейдите в Distributed Tracing.
- В верхней левой части страницы, под заголовком приложения, выберите Spans, чтобы просмотреть анализ на основе спанов запросов.
- В текстовом поле Search facets введите Span, а затем выберите internal в фасете Span kind.
- Прямо над таблицей раскройте выпадающий список Group by и выберите Services и Span name. У вас должна получиться следующая группировка: Group by: Service | Span name.
- Выберите заголовок таблицы Average duration.
- Выберите слева от текущего активного первичного атрибута, чтобы развернуть атрибут и просмотреть запрошенный анализ.
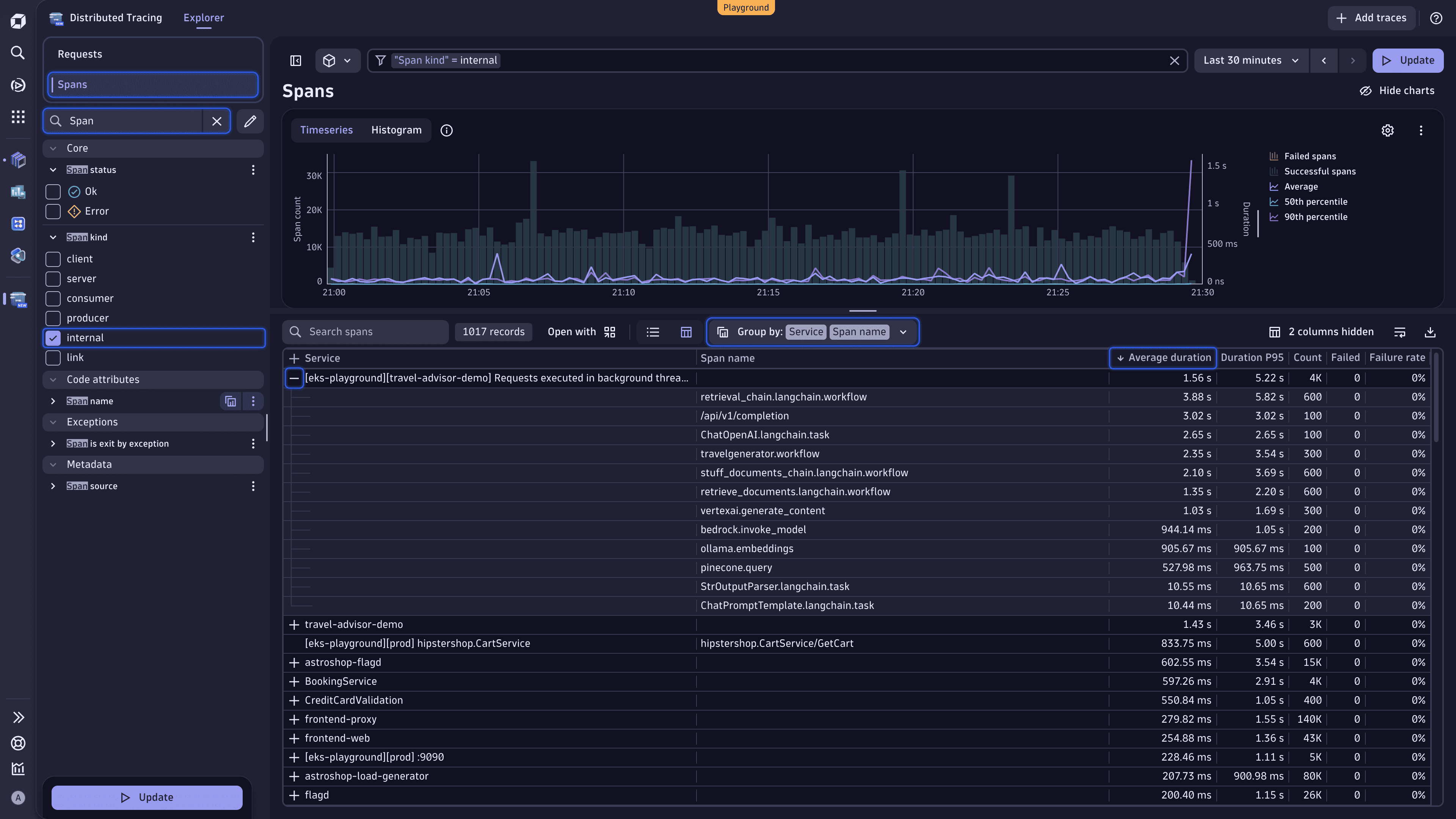
Вы можете мгновенно увидеть, какие спаны потребляют больше всего времени.
Определение топ-10 самых медленных внутренних спанов¶
Используя следующий запрос, вы получите список самых медленных внутренних узлов спанов по средней длительности.
Пояснение к DQL-запросу
fetch spans: Извлечение данных из таблицыspans, содержащей информацию об отдельных спанах.filter matchesValue(`span.kind`, "internal"): Фокус на внутренних спанах, исключая такие типы спанов, как HTTP-запросы или спаны обмена сообщениями.summarize {durationSum = sum(duration), callCount = count(), avgDuration = avg(duration)}, by: {service.name, span.name}: Агрегирование данных спанов по трём направлениям (общая длительность, количество вызовов и средняя длительность) и группировка данных по сервису и имени спана для получения метрик для каждого метода или операции в рамках каждого сервиса.sort avgDuration desc: Сортировка по средней длительности, начиная с наибольшей (то есть самых медленных внутренних операций).limit 10: Ограничение вывода 10 первыми результатами.
fetch spans
| filter matchesValue(`span.kind`, "internal")
| summarize {durationSum = sum(duration), callCount = count(), avgDuration = avg(duration)}, by: {service.name, span.name}
| sort avgDuration desc
| limit 10
Запустить в Playground
Выявление функции в вашем коде, которая потребляет значительное количество времени выполнения или ресурсов, помогает обнаруживать узкие места, понимать поведение во время выполнения и оптимизировать усилия (такие как снижение использования CPU, потребления памяти или времени отклика).
Выявление паттернов логов: сервисы с наибольшим количеством логов¶
Теперь давайте обнаружим сервисы, которые генерируют наибольшее количество логов. Запрос ниже предлагает нам простой способ определить наших основных генераторов логов в контексте трассировки.
Пояснение к DQL-запросу
fetch logs: Загрузка всех доступных данных логов из таблицыlogs.filter isNotNull(trace_id): Включение только тех логов, которые являются частью трассировки.summarize count = count(), by: {service.name}: Суммирование логов и группировка по имени сервиса, то есть мы считаем, сколько логов, связанных с трассировками, создал каждый сервис.sort count desc: Сортировка по количеству логов, начиная с наибольшего, так что сервисы с наибольшим количеством логов отображаются первыми.limit 20: Ограничение вывода 20 первыми результатами.
fetch logs
| filter isNotNull(trace_id)
| summarize count = count(), by: {service.name}
| sort count desc
| limit 20
Запустить в Playground
Такой DQL-запрос полезен, когда вам нужно понять, какие сервисы генерируют наибольшее количество логов. Зная это, вы можете выявить сервисы с чрезмерным логированием и оптимизировать затраты на приём логов.
Объединение логов и трассировок: подсчёт логов на конечную точку сервиса¶
Наконец, давайте узнаем, сколько логов создаётся для каждой конечной точки сервиса.
По умолчанию логи не содержат информации о конечной точке. Однако, обогащая логи идентификатором трассировки, мы можем выполнить join логов и трассировок на основе их общего поля.
Пояснение к DQL-запросу
fetch spans: Извлечение данных из таблицыspans, содержащей информацию об отдельных спанах.-
join [: Выполнение операции объединения с другим набором данных: -
fetch logs: Загрузка всех доступных данных логов из таблицыlogs. fieldsAdd trace.id = toUid(trace_id): Добавление поляtrace.idпутём преобразования поляtrace_idв уникальный идентификатор (UID) с помощью функцииtoUid.summarize logCount = count(), by: {trace.id}: Суммирование данных логов поtrace.id, вычисление общего количества логов для каждой трассировки.], on: {trace.id}: Объединение суммированных данных логов с данными спанов по полюtrace.id, совмещая два набора данных.filter isNotNull(http.url): Включение только тех спанов, которые содержат HTTP URL.summarize {requestCount = count(), logCount = sum(right.logCount)}, by: {http.url}: Суммирование количества запросов и количества логов для каждой запрошенной конечной точки (полеhttp.url).fieldsAdd logPerRequest = logCount / requestCount: Добавление поля, в котором вычисляется соотношение логов на запрос.sort logPerRequest desc: Сортировка по убыванию.
fetch spans
| join [
fetch logs
| fieldsAdd trace.id = toUid(trace_id)
| summarize logCount = count(), by: {trace.id}
], on: {trace.id}
| filter isNotNull(http.url)
| summarize {requestCount = count(), logCount = sum(right.logCount)}, by: {http.url}
| fieldsAdd logPerRequest = logCount / requestCount
| sort logPerRequest desc
Запустить в Playground
Выполняя этот запрос, мы получаем список, отсортированный по конечным точкам, который суммирует количество запросов и логов, полученных для каждой конечной точки, а также вычисляет соотношение логов на запрос. Это полезно для выявления наиболее нагруженных конечных точек, которые могут генерировать чрезмерное количество логов.
Призыв к действию¶
Мы надеемся, что это руководство дало вам дополнительные советы и приёмы, позволяющие стать более эффективными в анализе трассировок и логов, а также в обнаружении аномалий в вашей среде. Вы можете применять аналогичные техники к исключениям, хостам, процессам, удалённым вызовам процедур и многому другому.
Вы узнали, как использовать Distributed Tracing для обнаружения паттернов запросов к базе данных. Кроме того, вы освоили множество примеров использования DQL для поиска сервисов с наибольшим количеством исключений, выявления «горячих» методов и даже объединения логов и трассировок для подсчёта количества логов, созданных для каждой конечной точки сервиса.
Если вы считаете, что вам необходимо иметь определённую информацию под рукой, добавьте результат DQL-запроса на дашборд. Вы также можете рассмотреть возможность создания метрики, которую можно извлекать из логов по мере их поступления в Dynatrace.
Следующие шаги¶
- Ознакомьтесь с этим специальным ноутбуком, созданным в нашей среде Dynatrace Playground, где мы делимся некоторыми советами и приёмами использования трассировок, логов и DQL для выявления необычных паттернов в вашей среде.
- Погрузитесь глубже в мир DQL: посетите Dynatrace Query Language и лучшие практики DQL.
-
Изучите следующие приложения Dynatrace:
 Logs
Logs- Notebooks
 Dashboards
Dashboards