Расширенная аналитика трассировки на базе Grail
Расширенная аналитика трассировки на базе Grail предназначена для опытных пользователей, которым требуется продвинутый анализ трассировки, доступный через Дашборды, Ноутбуки, Workflows и через Dynatrace API.
Перед началом работы¶
Необходимые условия
- Убедитесь, что у вашего пользователя есть разрешения, необходимые для доступа к данным трассировки.
- Обзор трассировок на базе Grail (DPS).").
Предварительные знания
- Концепции распределённой трассировки
- Семантическая модель для трассировок
Доступ к спанам и атрибутам спанов через DQL¶
Спан представляет собой логическую единицу работы внутри трассировки и описывается атрибутами спана. Атрибуты спана устанавливаются инструментацией, которая создаёт спан, и предоставляют подробную информацию о спане, включая тип выполняемой операции и контекст его происхождения. Семантика всех полей документирована в Семантическом словаре Dynatrace. С помощью DQL вы можете:
- Получить доступ к каждому отдельному спану через команду
fetch spans. Комбинируйте её с функциями DQL для запроса любого атрибута спана, хранящегося в Grail, без дополнительной настройки. - Выполнять полнотекстовый поиск по любому атрибуту спана типа
stringс помощью строковых функций, доступных в DQL, таких какstartsWith,endsWith,containsилиmatchesPhrase.
Пример: доступ DQL ко всем спанам
Следующий пример запроса извлекает спаны с заголовком HTTP-запроса и для каждого спана отображает значения имени конечной точки, заголовка и метода HTTP-запроса и идентификатора трассировки.
fetch spans
| filter isNotNull( http.request.header.host)
| fields endpoint.name, http.request.header.host, http.request.method, trace.id
| limit 5
Результат запроса:
Пример: доступ DQL ко всем атрибутам
Следующий запрос извлекает спаны, сгенерированные с HTTP-маршрутом от сервера. Чтобы убедиться, что все спаны используют одно и то же имя поля для метода HTTP-запроса, он ищет два семантически разных поля и сохраняет первый результат в новое поле для консультационных целей. Затем он суммирует результаты по методу HTTP-запроса и HTTP-маршруту, предоставляя количество спанов, их среднюю продолжительность и значение продолжительности в 50-м процентиле.
fetch spans
| filter span.kind == "server" and isNotNull(http.route)
| fieldsAdd http.request.method = coalesce(http.request.method, http.method)
| summarize { count(), avg(duration), p50=percentile(duration, 50)}, by: { http.request.method, http.route }
| limit 3
Результат запроса:
Пример: полнотекстовый поиск
Следующий пример извлекает спаны с HTTP-маршрутом, содержащим user, и не заканчивающимся на username, и суммирует результаты, предоставляя количество спанов по методу HTTP-запроса и HTTP-маршруту.
fetch spans
| filterOut isNull(http.route)
| filter contains(http.route, "v1/") and not endsWith(http.route, "/sell")
| summarize count(), by: { http.request.method, http.route }
Результат запроса:
Дополнительные примеры см. в ноутбуке Введение в Dynatrace Playground.
HTTP-запросы и сетевое взаимодействие¶
Вы можете анализировать ваши веб-запросы с помощью DQL и:
- Получать информацию о продолжительности данных спанов через функцию
summarize. - Извлекать временные ряды из необработанных данных спанов через команду
makeTimeseriesи фильтровать результаты по любому атрибуту спана. - Анализировать запросы.
- Агрегировать результаты по идентификатору запроса (требуется OneAgent).
Пример: суммирование продолжительности
В следующем примере запрос извлекает спаны, содержащие HTTP-маршрут с определённым строковым значением (services), и суммирует результаты по продолжительности. Продолжительность выражена в корзинах с шагом 100 мс, упорядоченных от наименьшего к наибольшему значению. Каждая корзина агрегирует время отклика ряда спанов, которые представлены случайной трассировкой, выбранной из агрегированных значений.
fetch spans
// filter for specific HTTP route
| filter contains(http.route, "services")
| summarize {
spans=count(),
trace=takeAny(record(start_time, trace.id)) // pick random trace from aggregation bucket
}, by: { bin(duration, 100ms) }
| fields `bin(duration, 100ms)`, spans, trace.id=trace[trace.id], start_time=trace[start_time]
Результат запроса:
Пример: извлечение временного ряда
С помощью команды makeTimeseries вы можете извлечь временной ряд из необработанных данных спанов и использовать атрибуты спанов для фильтрации, агрегации или группировки результатов. Этот подход «на лету» превосходит ограничение материализованных временных рядов (метрик), которые требуют наборов измерений, определённых заранее.
Следующий запрос извлекает спаны, содержащие определённый HTTP-маршрут, и извлекает временной ряд на основе результатов.
fetch spans
// filter for specific http route
| filter contains(http.route, "services") and http.request.method == "GET"
// extract timeseries
| makeTimeseries { avg=avg(duration) }
, by: { http.route }, bins:250
Пример: анализ запросов
Запрос — это входящий вызов, идентифицируемый в Dynatrace парой ключ-значение request.is_root_span: true. Вы можете анализировать запросы с помощью функции fields для извлечения конкретной информации или отслеживать такие проблемы, как неудачные запросы, используя request.is_failed: true. Например, вы можете запрашивать неудачные запросы и отображать релевантные детали, включая связанную конечную точку, чтобы определить, где возникают проблемы.
Запросы обычно также содержат конечную точку — имя, представляющее определённый путь или ресурс в сервисе, куда направляются запросы. Она представляет собой точку входа для взаимодействий, например, маршрут API — такой как /api/orders — или метод.
Следующий запрос извлекает неудачные запросы и отображает значения указанных полей.
fetch spans
// filter only for request root spans
| filter request.is_root_span == true
| filter request.is_failed == true
| fields trace.id, span.id, start_time, response_time = duration, endpoint.name
| limit 100
Пример: агрегация запросов по идентификатору запроса (требуется OneAgent)
В следующем примере цель состоит в сборе информации о дочерних спанах запросов. request.id используется для агрегации результатов, поскольку все спаны, принадлежащие одному запросу, несут его идентификатор.
fetch spans
// request.id is pre-requisite for this query. not always present
| filter isNotNull(request.id)
| summarize {
spans = count(),
client_spans = countIf(span.kind == "client"),
span_events = sum(arraySize(span.events)),
// from all spans in the summarized group, select the one that is the request root
request_root = takeMin(record(
root_detection_helper = coalesce(if(request.is_root_span, 1), 2 /* INVALID */),
start_time, endpoint.name, duration
))
}, by: { trace.id, request.id }
// reset request_root to NULL if root_detection_helper is invalid
| fieldsAdd request_root=if(request_root[root_detection_helper] < 2, request_root)
| fieldsFlatten request_root | fieldsRemove request_root.root_detection_helper, request_root
| fields
start_time = request_root.start_time,
endpoint = request_root.endpoint.name,
response_time = request_root.duration,
spans,
client_spans, span_events,
trace.id
| limit 100
Пример: агрегация трассировок
Полная трассировка состоит из множества спанов. Обычно вы хотите идентифицировать трассировку по первому запросу, с которого она началась, — «корневому запросу».
Следующий запрос находит корневой спан запроса и дополнительно выполняет агрегации по всей трассировке на основе агрегации по trace.id.
fetch spans
| summarize {
spans = count(),
client_spans = countIf(span.kind == "client"),
span_events = sum(arraySize(span.events)),
// endpoints involved in the trace
endpoints = toString(arrayRemoveNulls(collectDistinct(endpoint.name))),
// hosts involved in the trace
hosts = arrayRemoveNulls(collectDistinct(host.name)),
// from all spans in the summarized group, select the one that is the first request root in the trace
trace_root = takeMin(record(
root_detection_helper = coalesce(if(request.is_root_span, 1), if(isNull(span.parent_id), 2), 3),
start_time, endpoint.name, duration
))
}, by: { trace.id }
| fieldsFlatten trace_root | fieldsRemove trace_root.root_detection_helper, trace_root
| fields
start_time = trace_root.start_time,
endpoint = trace_root.endpoint.name,
response_time = trace_root.duration,
spans,
client_spans, span_events,
endpoints, hosts,
trace.id
| sort start_time
| limit 100
Пример: атрибуты запросов
Атрибуты запросов представлены как атрибуты спана в «корневом спане запроса» (request.is_root: true) с ключом: request_attribute.name of the <request attribute>.
Если имя атрибута запроса содержит специальные символы, необходимо использовать обратные кавычки.
fetch spans
// no backticks required
| filter isNotNull(request_attribute.my_customer_id)
// backticks required
| filter isNotNull(`request_attribute.My Customer ID`)
Тип данных request_attribute.* зависит от конфигурации атрибута запроса. Если конфигурация установлена на «Все значения», типом данных является массив.
Если атрибут запроса настроен для захвата из параметров метода, существуют дополнительные атрибуты на спане, где атрибут был захвачен, с ключом captured_attribute.<name of the request attribute>. Тип данных captured_attribute.* всегда является массивом, поскольку во время захвата неизвестно, будет ли одно или несколько значений.
Дополнительные примеры см. в ноутбуке HTTP-запросы и сетевое взаимодействие в Dynatrace Playground.
Базы данных¶
Вы можете анализировать ваши базы данных с помощью DQL для трассировок.
Пример: 10 наиболее частых запросов к базе данных
Этот запрос определяет 10 наиболее часто выполняемых запросов к базе данных из клиентских спанов по всем вашим данным телеметрии и группирует их по системе базы данных, имени операции и тексту запроса.
fetch spans
| filter isNotNull(db.namespace) AND span.kind == "client"
| summarize by:{db.system, db.operation.name, db.query.text}, count = count()
| sort count desc
| limit 10
Пример: основные запросы к базе данных по сервисам
Этот запрос определяет 10 основных запросов к базе данных, выполняемых каждым сервисом, вместе с общим количеством вызовов для каждого запроса. Он учитывает сэмплирование и агрегацию для предоставления точного подсчёта вызовов базы данных.
fetch spans
// filter for database spans
| filter span.kind == "client" and isNotNull(db.namespace)
// add service name
| fieldsAdd entityName = dt.entity.service
// calculate multiplicity factor for every span, to for extrapolations
| fieldsAdd sampling.probability = (power(2, 56) - coalesce(sampling.threshold, 0)) * power(2, -56)
| fieldsAdd sampling.multiplicity = 1/sampling.probability
| fieldsAdd multiplicity = coalesce(sampling.multiplicity, 1)
* coalesce(aggregation.count, 1)
* dt.system.sampling_ratio
| summarize { db_calls = sum(multiplicity) }, by: { dt.entity.service.name, code.function, db.system, db.namespace, db.query.text }
// top 100
| sort db_calls desc
| limit 10
Пример: вызовы базы данных по конечным точкам в виде временного ряда
Этот запрос определяет 10 основных вызовов базы данных к каждой конечной точке во времени. Он учитывает сэмплирование и агрегацию для предоставления точного подсчёта вызовов базы данных.
fetch spans
// calculate multiplicity factor for every span, to for extrapolations
| fieldsAdd sampling.probability = (power(2, 56) - coalesce(sampling.threshold, 0)) * power(2, -56)
| fieldsAdd sampling.multiplicity = 1/sampling.probability
| fieldsAdd multiplicity = coalesce(sampling.multiplicity, 1)
* coalesce(aggregation.count, 1)
* dt.system.sampling_ratio
| summarize {
spans = count(),
db_spans = countIf(span.kind == "client" and isNotNull(db.namespace)),
db_calls = sum(if(span.kind == "client" and isNotNull(db.namespace), multiplicity, else: 0) ),
// from all spans in the summarized group, select the one that is the request root
request_root = takeMin(record(
root_detection_helper = coalesce(if(isNotNull(endpoint.name), 1), 2),
start_time, endpoint.name, duration
))
}, by: { trace.id, request.id }
| fields
start_time = request_root[start_time],
endpoint = request_root[endpoint.name],
respopnse_time = request_root[duration],
spans,
db_spans, db_calls,
trace.id
| makeTimeseries { avg(db_calls) }, by: { endpoint }
// only show top 10 timeseries
| sort arraySum(`avg(db_calls)`) desc
| limit 10
Пример: ошибки базы данных
Этот запрос определяет 10 основных ошибок базы данных, возникающих в клиентских спанах, и группирует их по системе базы данных и тексту запроса.
fetch spans
// filter for database spans
| filter span.kind == "client"
| filter isNotNull(span.events)
| filter db.namespace != ""
| filter isNotNull(db.query.text)
| filter eventname == "exception"
// adds service name
| fieldsAdd entityName(dt.entity.service)
// adds the error message
| fieldsAdd exception = span.events[0][exception.message]
// adds span name
| fieldsAdd eventname = span.events[0][span_event.name]
| summarize {ExceptionMessage = collectDistinct(exception),
Errors = count()},
by:{Database = db.namespace, Query = db.query.text}
// only show top 10 errors
| sort Errors desc
| limit 10
Результат запроса:
Дополнительные примеры см. в ноутбуке Базы данных в Dynatrace Playground.
Исключения¶
Исключения, возникающие в контексте распределённой трассировки, хранятся внутри отдельных спанов в виде списка span.events. Вы можете запрашивать эти исключения с помощью команды DQL iAny. Вы также можете развернуть и выровнять события спана, чтобы атрибуты исключений отображались как атрибуты верхнего уровня. С помощью этого легко создавать временные ряды или любые другие агрегации из исключений.
Значение каждого атрибута имеет тип string, что делает его доступным для поиска, и это также применимо к сообщениям исключений и стекам вызовов. Кроме того, вы можете применить команду DQL parse для извлечения структурированной информации.
Пример: поиск исключений с исключением определённых типов
Этот запрос извлекает спаны, содержащие события ошибок, с акцентом на исключения, не связанные с HTTP.
fetch spans
// only spans which contain a span event of type "exception"
| filter iAny(span.events[][span_event.name] == "error")
// exclude specific exception
| filter iAny(contains(span.events[][span_event.name], "http"))
// make exception attributes top level attributes
| expand span.events
| fields span.events
| fieldsFlatten span.events
| fieldsRemove span.events
| limit 1000
Пример: полнотекстовый поиск
Этот запрос выполняет полнотекстовый поиск по стеку вызовов спанов для нахождения определённых сообщений об ошибках.
fetch spans
// full text search on stacktrace
| filter iAny(contains(span.events[][exception.stack_trace], "hang up"))
// make exception attributes top level attributes
| expand span.events
| fields span.events
| fieldsFlatten span.events
| limit 1000
Пример: подсчёт исключений по типу
Этот запрос подсчитывает количество исключений по их типу.
fetch spans
// only spans which contain a span event of type "exception"
| filter iAny(span.events[][span_event.name] == "exception")
// make exception type top level attribute
| expand span.events
| fieldsFlatten span.events, fields: { exception.type }
| summarize count(), by: { exception.type }
Результат запроса:
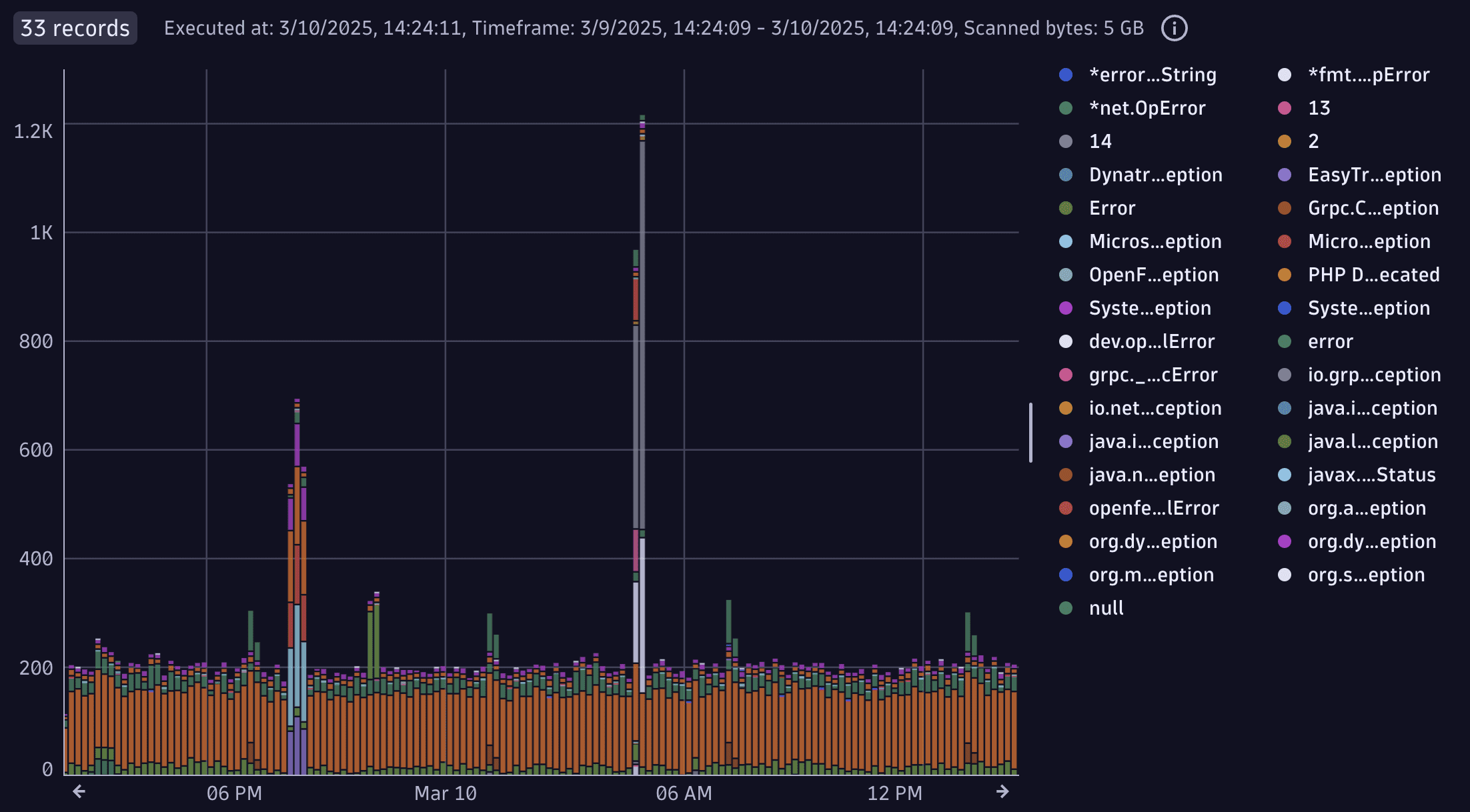
Пример: частота исключений в виде графика
Этот запрос создаёт график временного ряда, показывающий частоту исключений по их типу.
fetch spans
// only spans which contain a span event of type "exception"
| filter iAny(span.events[][span_event.name] == "exception")
// make exception type top level attribute
| expand span.events
| fieldsFlatten span.events, fields: { exception.type }
| makeTimeseries count(), by: { exception.type }
Результат запроса:
Пример: использование команды parse для извлечения информации
Этот запрос извлекает структурированную информацию из сообщений исключений с помощью команды parse.
fetch spans
| filter iAny(contains(span.events[][exception.message], "Bio for user with id"))
// make exception attributes top level attributes
| expand span.events
| fields span.events
| fieldsFlatten span.events
| fieldsRemove span.events
// parse "user_id" number from the exception message
// Example message: "Bio for user with id '9146' not found"
| parse `span.events.exception.message`, "Bio for user with id \'INT:user_id\' not found"
| summarize count(), by: { user_id }
// show top 5
| sort `count()` desc
| limit 5
Результат запроса:
Дополнительные примеры см. в ноутбуке Исключения в Dynatrace Playground.
Логи¶
Логи могут быть обогащены trace_id и span_id. OneAgent может даже автоматически обогащать такой контекст в логах. С этой информацией вы можете объединять спаны и логи, чтобы, например, находить трассировки и спаны, которые генерируют определённые логи.
Пример: логи с контекстом трассировки
Этот запрос извлекает логи, обогащённые информацией о контексте трассировки.
Пример: поиск спанов, содержащих определённую строку
Этот запрос извлекает спаны, содержащие определённую строку в своих атрибутах.
fetch spans
| filter trace.id in [
fetch logs
// only logs that have a trace context
| filter isNotNull(trace_id)
// search for a particular string in logs content
| filter contains(content, "No carts for user")
// convert from string to UID type
| fields toUid(trace_id)
]
| limit 5
Пример: из логов с определённой строкой показать производительность спанов, в которых был сгенерирован лог
Этот запрос извлекает спаны, которые были активны, когда было сгенерировано определённое сообщение лога.
fetch spans
| filter span.id in [
fetch logs
// only logs that have a trace context
| filter isNotNull(span_id)
| filter contains(content, "No carts for user")
// convert from string to UID type
| fields toUid(span_id)
]
// pick either the span name or code namespace and function, depending on what's available
| fieldsAdd name = coalesce(span.name, concat(code.namespace, ".", code.function))
| summarize { count(), avg(duration), p99=percentile(duration, 99), trace.id=takeAny(trace.id) } , by: { k8s.pod.name, name }
Пример: объединение спанов и логов
Этот запрос объединяет спаны с логами на основе идентификатора трассировки.
fetch spans
| fieldsAdd trace_id = toString(trace.id)
| join [ fetch logs ]
, on:{ left[trace_id] == right[trace_id] }
, fields: { content, loglevel }
| fields start_time, trace.id, span.id, code=concat(code.namespace, ".", code.function), loglevel, content
| limit 100
Дополнительные примеры см. в ноутбуке Логи в Dynatrace Playground.
Сэмплирование, агрегация и экстраполяция¶
Сэмплирование
: * Адаптивное управление трафиком (ATM) — это механизм сэмплирования на основе ограничения скорости, который адаптивно реагирует на частоту запросов. Решение принимается на агенте в начале трассировки (поэтому «head-based»).
* Адаптивное снижение нагрузки (ALR) — это серверный механизм сэмплирования, направленный на защиту серверной инфраструктуры от перегрузки.
* Сэмплирование при чтении
* С помощью сэмплирования при чтении вы можете контролировать объём данных, которые должны быть прочитаны в запросе, через параметр samplingRatio.
* При значении больше 1 читается только выборочная доля данных.
* Доступны следующие коэффициенты сэмплирования: 1, 10, 100, 1000, 10000, 100000. Где 1 означает 100% данных, а 100 означает 1% данных.
* Фактически применённый коэффициент сэмплирования при чтении можно использовать через dt.system.sampling_ratio. Даже если samplingRatio установлен на samplingRatio: 17, Grail может решить вернуться к фактическому коэффициенту сэмплирования 10.
* Сэмплирование при чтении учитывает трассировки. Это означает, что в пределах определённого коэффициента сэмплирования вы найдёте либо все спаны трассировки, либо ни одного (на основе общего trace.id).
Агрегация
: Определённые типы операций одного типа могут быть агрегированы в один спан для оптимизации и уменьшения количества спанов. Примером являются спаны базы данных. Если существует много операций базы данных с одним и тем же запросом к одной и той же базе данных, OneAgent может решить агрегировать их. Такие агрегированные спаны можно идентифицировать по наличию атрибута aggregation.count.
Экстраполяция : Чтобы учесть всё это при подсчёте операций, необходимо экстраполировать количество спанов до фактического количества операций, используя правильный коэффициент экстраполяции:
```
// calculate multiplicity factor for every span, to for extrapolations
| fieldsAdd sampling.probability = (power(2, 56) - coalesce(sampling.threshold, 0)) * power(2, -56)
| fieldsAdd sampling.multiplicity = 1/sampling.probability
| fieldsAdd multiplicity = coalesce(sampling.multiplicity, 1)
* coalesce(aggregation.count, 1)
* dt.system.sampling_ratio
```
Чтобы использовать экстраполяцию, например, для подсчёта количества запросов, необходимо использовать `sum()`:
```
| summarize count = sum(multiplicity)
```
Пример: подсчёт запросов с экстраполяцией
Этот запрос подсчитывает количество запросов с применённой экстраполяцией.
fetch spans
// read only 1% of data for better read performance
, samplingRatio:100
// only request roots
| filter request.is_root_span == true
// calculate multiplicity factor for every span, to for extrapolations
| fieldsAdd sampling.probability = (power(2, 56) - coalesce(sampling.threshold, 0)) * power(2, -56)
| fieldsAdd sampling.multiplicity = 1/sampling.probability
| fieldsAdd multiplicity = coalesce(sampling.multiplicity, 1)
* coalesce(aggregation.count, 1)
* dt.system.sampling_ratio
| summarize span_count=count(), request_count_extrapolated = sum(multiplicity)
Результат запроса:
Пример: подсчёт и продолжительность вызовов базы данных с экстраполяцией
Этот запрос подсчитывает количество вызовов базы данных с применённой экстраполяцией.
fetch spans
// read only 1% of data for better read performance
, samplingRatio:100
// only database spans
| filter isNotNull(db.statement)
// calculate multiplicity factor for every span, to for extrapolations
| fieldsAdd sampling.probability = (power(2, 56) - coalesce(sampling.threshold, 0)) * power(2, -56)
| fieldsAdd sampling.multiplicity = 1/sampling.probability
| fieldsAdd multiplicity = coalesce(sampling.multiplicity, 1)
* coalesce(aggregation.count, 1)
* dt.system.sampling_ratio
| fieldsAdd aggregation.duration_avg = coalesce(aggregation.duration_sum / aggregation.count, duration)
| summarize {
operation_count_extrapolated = sum(multiplicity),
operation_duration_extrapolated = sum(aggregation.duration_avg * multiplicity) / sum(multiplicity)
}
Результат запроса:
Дополнительные примеры см. в ноутбуке Сэмплирование, агрегация и экстраполяция в Dynatrace Playground.
Использование запросов к трассировкам¶
Изучите использование запросов к трассировкам с точки зрения биллинга. Узнайте об использовании по приложениям, пользователям и типу запроса.
Пример: использование запросов к трассировкам для приложений
Этот запрос анализирует данные использования биллинга, связанные с запросами к трассировкам, с целью разбивки потребления данных и объёма запросов по приложению и пользователю.
fetch dt.system.events
| filter event.kind == "BILLING_USAGE_EVENT"
| filter event.type == "Traces - Query"
| dedup event.id
| summarize {
data_read_GiB = sum(billed_bytes / 1024 / 1024 / 1024.0),
Query_count = count()
}, by: {
App_context = client.application_context, application_detail = client.source, User = user.email
}
| fieldsAdd split_by_user = record(data_read_GiB, App_context, application_detail, User, Query_count)
| summarize {
split_by_user = arraySort(collectArray(split_by_user), direction: "descending"),
data_read_GiB = sum(data_read_GiB),
Query_count = sum(Query_count)
}, by:{
App_context, application_detail
}
| fieldsAdd split_by_user = record(App_context = split_by_user[][App_context], application_detail = split_by_user[][application_detail], User = split_by_user[][User], data_read_GiB = split_by_user[][data_read_GiB], data_read_pct = (split_by_user[][data_read_GiB] / data_read_GiB * 100), Query_count = split_by_user[][Query_count])
| fieldsAdd split_by_user = if(arraySize(split_by_user) == 1, arrayFirst(split_by_user)[User], else: split_by_user)
| fieldsAdd application_details = record(data_read_GiB, App_context, application_detail, split_by_user, Query_count)
| summarize {
application_details = arraySort(collectArray(application_details), direction: "descending"),
data_read_GiB = sum(data_read_GiB),
Query_count = toLong(sum(Query_count))
}, by:{
App_context
}
| fieldsAdd application_details = record(App_context = application_details[][App_context], application_detail = application_details[][application_detail], split_by_user = application_details[][split_by_user], data_read_GiB = application_details[][data_read_GiB], data_read_pct = application_details[][data_read_GiB] / data_read_GiB * 100, Query_count = application_details[][Query_count])
| fieldsAdd key = 1
| fieldsAdd total = lookup([
fetch dt.system.events
| filter event.kind == "BILLING_USAGE_EVENT" and event.type == "Traces - Query"
| dedup event.id
| summarize total = sum(billed_bytes / 1024 / 1024 / 1024.0)
| fieldsAdd key = 1
], sourceField: key, lookupField:key)[total]
| fields App_context, application_details, data_read_GiB, data_read_pct = data_read_GiB / total * 100, Query_count
| sort data_read_GiB desc
Пример: использование запросов к трассировкам по пользователям
Этот запрос предоставляет подробную разбивку использования биллинга запросов к трассировкам по пользователям, фокусируясь на том, сколько данных потребляет каждый пользователь и через какие контексты приложений.
fetch dt.system.events
| filter event.kind == "BILLING_USAGE_EVENT"
| filter event.type == "Traces - Query"
| dedup event.id
| summarize {
data_read_GiB = sum(billed_bytes / 1024 / 1024 / 1024.0),
Query_count = count()
}, by: {
App_context = client.application_context, application_detail = client.source, User = user.email
}
| fieldsAdd split_by_application_detail = record(data_read_GiB, App_context, application_detail, User, Query_count)
| summarize {
split_by_application_detail = arraySort(collectArray(split_by_application_detail), direction: "descending"),
data_read_GiB = sum(data_read_GiB),
Query_count = sum(Query_count)
}, by:{
User, App_context
}
| fieldsAdd split_by_application_detail = record(User = split_by_application_detail[][User], App_context = split_by_application_detail[][App_context], application_detail = split_by_application_detail[][application_detail], data_read_GiB = split_by_application_detail[][data_read_GiB], data_read_pct = (split_by_application_detail[][data_read_GiB] / data_read_GiB * 100), Query_count = split_by_application_detail[][Query_count])
| fieldsAdd split_by_application_detail = if(arraySize(split_by_application_detail) == 1, arrayFirst(split_by_application_detail)[application_detail], else: split_by_application_detail)
| fieldsAdd App_contexts = record(data_read_GiB, User, App_context, split_by_application_detail, Query_count)
| summarize {
App_contexts = arraySort(collectArray(App_contexts), direction: "descending"),
data_read_GiB = sum(data_read_GiB),
Query_count = toLong(sum(Query_count))
}, by:{
User
}
| fieldsAdd App_contexts = record(User = App_contexts[][User], App_context = App_contexts[][App_context], split_by_application_detail = App_contexts[][split_by_application_detail], data_read_GiB = App_contexts[][data_read_GiB], data_read_pct = App_contexts[][data_read_GiB] / data_read_GiB * 100, Query_count = App_contexts[][Query_count])
| fieldsAdd key = 1
| fieldsAdd total = lookup([
fetch dt.system.events
| filter event.kind == "BILLING_USAGE_EVENT" and event.type == "Traces - Query"
| dedup event.id
| summarize total = sum(billed_bytes / 1024 / 1024 / 1024.0)
| fieldsAdd key = 1
], sourceField: key, lookupField:key)[total]
| fields User, App_contexts, data_read_GiB, data_read_pct = data_read_GiB / total * 100, Query_count
| sort data_read_GiB desc
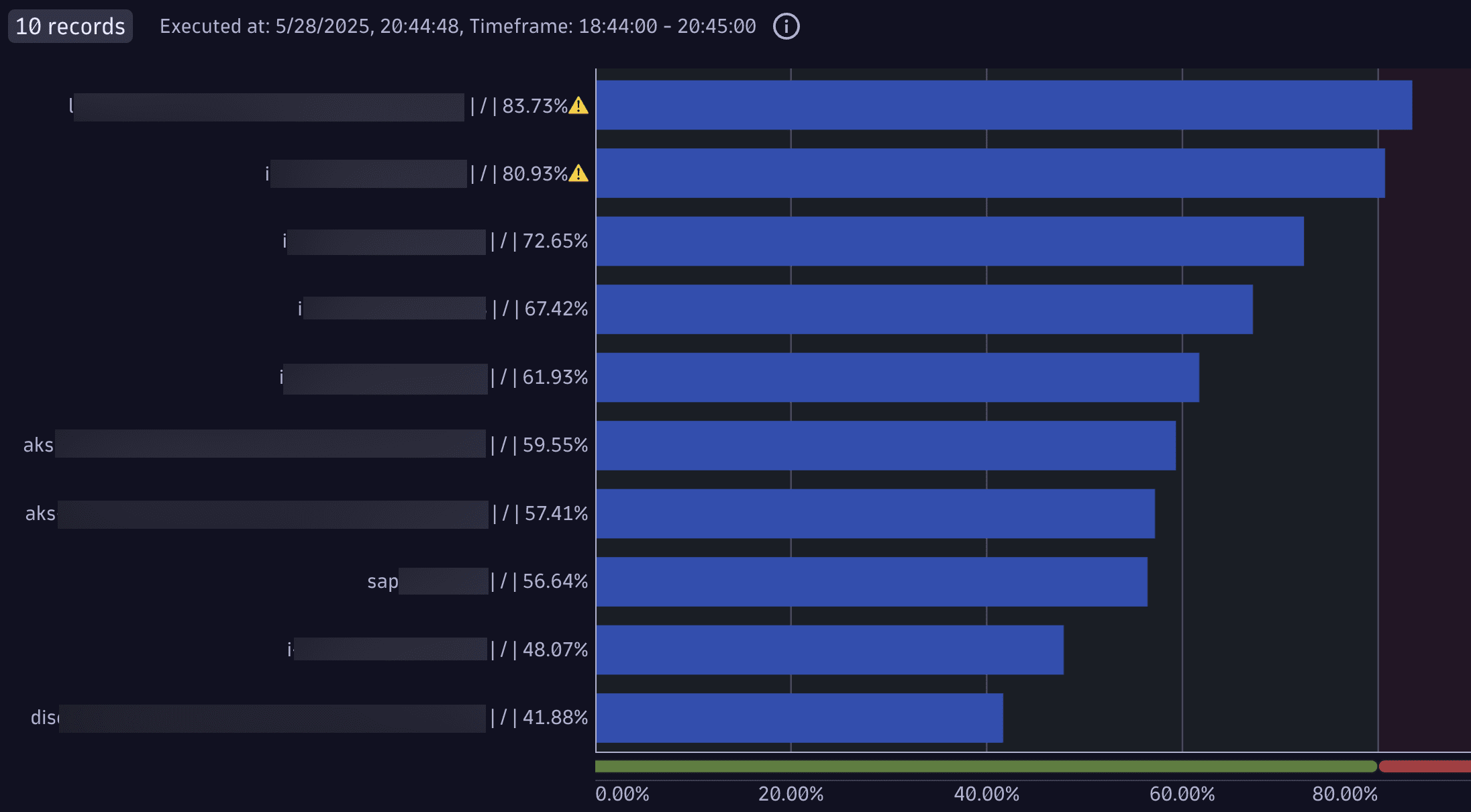
Пример: Топ-10 дисков с наибольшим средним использованием
Этот запрос определяет 10 дисков с наибольшим средним использованием на хостах. Он вычисляет средний процент использования диска для каждой пары диск-хост, а затем вычисляет общее среднее для каждой комбинации.
timeseries percent = avg(dt.host.disk.used.percent), by:{dt.entity.host, dt.entity.disk}
| fieldsAdd percent = arrayAvg(percent)
| fieldsAdd display = concat(entityName(dt.entity.host), " | ", entityName(dt.entity.disk), " | " , round(percent, decimals:2), "%", if(percent>80, "⚠️"))
| sort percent desc
| limit 10
Результат запроса:
Дополнительные примеры см. в ноутбуке Использование запросов к трассировкам в Dynatrace Playground.
Связанные темы¶
- Концепции распределённых трассировок
- Dynatrace Query Language