Расчёт потребления Full-Stack Monitoring (DPS)
- Актуальная версия Dynatrace
- Пояснение
Full-Stack Monitoring для хостов и контейнеров предлагает комплексный мониторинг производительности приложений. Мониторинг производительности приложений включает: распределённую трассировку, видимость на уровне кода, профилирование CPU, профилирование памяти и глубокий мониторинг процессов для хостов и контейнеров.
-
Full-Stack Monitoring на основе хостов:
-
Потребление основано на памяти хоста, см. ГиБ-часы.
-
Дополнительно предлагает все функции Infrastructure Monitoring.
-
Дополнительно предлагает все функции Kubernetes Platform Monitoring.")1 2.
-
Расширения Dynatrace Extensions могут быть включены на хостах с Full-Stack Monitoring на основе хостов и могут потреблять пользовательские точки данных метрик Full-Stack и Log Analytics.
- Full-Stack Monitoring на основе контейнеров (application-only): Потребление основано на памяти контейнера, см. Расчёт ГиБ-часов для мониторинга контейнеров application-only3.
Чтобы узнать больше о поддерживаемых платформах, см. Матрица поддержки платформ и возможностей OneAgent.
1
Full-Stack Monitoring на основе хостов включает Kubernetes Platform Monitoring для всех подов, работающих на хостах с Full-Stack мониторингом. Поды, работающие на хостах без Full-Stack мониторинга, и поды в состоянии Pending не включены в Full-Stack Monitoring на основе хостов. Эти два типа подов тарифицируются за под-час, как описано в Kubernetes Platform Monitoring.
2
Для включения Kubernetes Platform Monitoring в Full-Stack Monitoring на основе хостов необходим OneAgent версии 1.301+. Если у вас OneAgent версии 1.300 или более ранней, Kubernetes Platform Monitoring будет по-прежнему доступен, но будут применяться тарифы за под-час, как описано в Kubernetes Platform Monitoring.
3
Full-Stack Monitoring на основе контейнеров (application-only) не включает Infrastructure Monitoring или Kubernetes Platform Monitoring.
ГиБ-часы¶
Dynatrace использует ГиБ-часы (упоминаемые как «memory-gibibyte-hours» в вашем тарифном плане) в качестве единицы измерения для расчёта потребления мониторинга хостов вашей организацией в режиме Full-Stack Monitoring. Чем больше памяти у хоста и чем дольше хост отслеживается, тем выше количество ГиБ-часов, потребляемых хостом.
Преимущество подхода ГиБ-часов к потреблению мониторинга — его простота и прозрачность. Технологически-специфические факторы (например, количество JVM или количество микросервисов, размещённых на сервере) не влияют на потребление. Не имеет значения, работает ли хост под управлением Kubernetes или других контейнеризованных приложений, приложений на основе .NET, Java или чего-то другого. У вас может быть 10 или 1000 JVM; такие факторы не влияют на потребление мониторинга среды.
Гранулярность тарификации для потребления ГиБ-часов¶
Dynatrace создан для динамических облачных сред, где хосты и сервисы быстро создаются и уничтожаются. Поэтому гранулярность тарификации для потребления ГиБ-часов рассчитывается 15-минутными интервалами. Когда хост или контейнер отслеживается менее 15 минут в интервале, потребление ГиБ-часов округляется до 15 минут перед расчётом потребления.
Расчёт ГиБ-часов для физических хостов и виртуальных машин (ВМ)¶
Каждый установленный экземпляр Dynatrace OneAgent, работающий на экземпляре операционной системы (развёрнутый, например, на физической или виртуальной машине) в режиме Full-Stack Monitoring, потребляет ГиБ-часы на основе физической или виртуальной оперативной памяти отслеживаемого хоста, рассчитанные 15-минутными интервалами (см. пример диаграммы ниже).
Оперативная память каждой ВМ или хоста округляется до следующего кратного 0,25 ГиБ (что равно 256 МиБ) перед расчётом потребления мониторинга. К потреблению ГиБ-часов для физических и виртуальных хостов применяется минимум 4 ГиБ. Например, хост с 8,3 ГиБ памяти считается как хост с 8,5 ГиБ, что является следующим кратным 0,25 ГиБ, а хост с 2 ГиБ памяти считается как хост с 4 ГиБ (округление не требуется, но применяется минимум 4 ГиБ).
Расчёт ГиБ-часов для мониторинга контейнеров application-only¶
В облачных средах сервисы и хосты часто являются кратковременными. Поэтому расчёт потребления мониторинга 15-минутными интервалами, а не полными часами, лучше отражает фактическое использование. Контейнеры, являющиеся важным механизмом в облачных средах, обычно используют меньше памяти, чем хосты. Поэтому минимальный порог памяти для контейнеров составляет 256 МиБ, а не 4 ГиБ — минимальный порог памяти для хостов.
Такое же округление, как и для хостов, до следующего кратного 0,25 ГиБ, также применяется к контейнерам. Например, контейнер с 780 МиБ памяти считается как контейнер с 1 ГиБ (780 МиБ, что равно 0,78 ГиБ, округляется до следующего кратного 0,25 ГиБ).
На рисунке ниже показано, как память учитывается при расчётах потребления ГиБ-часов с 15-минутными интервалами. Каждый интервал делится на четыре для получения единицы измерения потребления ГиБ-часов.

Расчёты объёма памяти¶
Расчёты объёма памяти для контейнеров, отслеживаемых в режиме application-only, основаны на одном из следующих параметров:
-
Используемая память контейнера.
-
OneAgent версии 1.275+ (для контейнеров Kubernetes)
- OneAgent версии 1.297+ (для бессерверных контейнеров)
-
Определённые контейнером лимиты памяти. Если лимит памяти не установлен, вместо него используется память базовой виртуальной машины.
-
OneAgent версии <1.275 (для контейнеров Kubernetes)
- OneAgent версии <1.297 (для бессерверных контейнеров)
Для существующих тенантов необходимо включить автоматическое обнаружение контейнеров.
Определённые сценарии мониторинга имеют собственные расчёты потребления ГиБ-часов, как описано в таблице ниже.
| Сценарий | Описание |
|---|---|
| Azure App Services (работающие на плане App Service (dedicated) для Windows) | Потребление основано на количестве и памяти экземпляров плана. Не имеет значения, сколько приложений работает на экземплярах. Минимальная тарифицируемая память составляет 256 МиБ (вместо 4 ГиБ). |
| Azure App Service (работающий на Linux OS или контейнерах Linux) OneAgent версии 1.297+ | Если автоматическое обнаружение контейнеров включено: потребление основано на используемой памяти контейнера. Если автоматическое обнаружение контейнеров не включено: потребление основано на памяти экземпляра плана, умноженной на количество работающих контейнеров. |
| Azure App Service (работающий на Linux OS или контейнерах Linux) OneAgent версии <1.297 | Потребление основано на памяти экземпляра плана, умноженной на количество работающих контейнеров, независимо от того, включено ли автоматическое обнаружение контейнеров или нет. |
| Oracle Solaris Zones | Solaris Zones считаются как хосты. |
| Отслеживаемые контейнеры, не обнаруженные как контейнеры | Эти контейнеры считаются как хосты. |
Метрики¶
В этом разделе предполагается, что вы следовали рекомендованным Dynatrace вариантам развёртывания, особенно в отношении обогащения телеметрии. Если вы реализуете пользовательское развёртывание, тарификация включённых метрик может по-прежнему работать как описано, но это не гарантируется Dynatrace.
Для получения дополнительной информации см. Поддерживаемые варианты развёртывания.
Full-Stack Monitoring включает все метрики Infrastructure Monitoring, метрики мониторинга производительности приложений и другие встроенные метрики. Эти метрики включены и никогда не создают дополнительных расходов.
Full-Stack Monitoring также включает определённый объём пользовательских точек данных метрик. Каждый вносящий вклад ГиБ памяти хоста или приложения добавляет 900 пользовательских точек данных метрик в каждом 15-минутном интервале. Включённые точки данных метрик, не использованные в 15-минутном интервале, в котором они были предоставлены, не переносятся на последующие интервалы. Включённые точки данных метрик вашей среды автоматически применяются к метрикам, которые исходят от хостов и контейнеров, отслеживаемых OneAgent в режиме Full-Stack Monitoring.
Все ключи метрик, начинающиеся с dt.service.*, предназначены для мониторинга сервисов и потребляют включённые точки данных метрик Full-Stack, если данные спанов исходят от хостов и контейнеров, отслеживаемых OneAgent в режиме Full-Stack Monitoring.
Если данные спанов исходят из другого источника, эти метрики тарифицируются как Metrics powered by Grail.
Такие ключи метрик включают, например:
dt.service.request.countdt.service.request.failure_countdt.service.request.response_timedt.service.request.service_mesh.countdt.service.request.service_mesh.failure_countdt.service.request.service_mesh.response_timedt.service.messaging.process.countdt.service.messaging.process.failure_countdt.service.messaging.publish.countdt.service.messaging.receive.count
Точки данных метрик, превышающие ваш включённый объём, тарифицируются как:
- Если Metrics powered by Grail есть в вашем тарифном плане, они тарифицируются как Metrics powered by Grail.
- Если Metrics powered by Grail нет в вашем тарифном плане, они тарифицируются как Custom Metrics Classic.
Включённые точки данных метрик вашей среды автоматически применяются к метрикам, которые исходят от хостов и контейнеров, отслеживаемых OneAgent в режиме Full-Stack Monitoring. Это применяется к пользовательским метрикам, как описано в таблице ниже.
1
Точки данных метрик, исходящие от Application Observability, включены только если Обзор Metrics powered by Grail (DPS) есть в вашем тарифном плане.
2
Точки данных метрик, отправленные через Dynatrace Collector, включены только если Обзор Metrics powered by Grail (DPS) есть в вашем тарифном плане.
3
Точки данных метрик, отправленные через OpenTelemetry Collector, включены только если Обзор Metrics powered by Grail (DPS) есть в вашем тарифном плане и OpenTelemetry Collector настроен, как описано в Обогащение OTLP-запросов данными Kubernetes.
Пример расчёта включённых точек данных метрик¶
Рассматривая пример, показанный на рисунке 1, ниже приведены расчёты включённых объёмов точек данных метрик для каждого из четырёх 15-минутных интервалов, при условии объёма в 900 включённых точек данных метрик для каждого 15-минутного интервала.
- Первый 15-минутный интервал:
900 (включённых точек данных метрик) x 13,5 (ГиБ памяти) = 12 150 включённых точек данных метрик - Второй 15-минутный интервал:
900 (включённых точек данных метрик) x 9,5 (ГиБ памяти) = 8 550 включённых точек данных метрик - Третий 15-минутный интервал:
900 (включённых точек данных метрик) x 8,75 (ГиБ памяти) = 7 875 включённых точек данных метрик - Четвёртый 15-минутный интервал:
900 (включённых точек данных метрик) x 0,25 (ГиБ памяти) = 225 включённых точек данных метрик
Как потребляются точки данных метрик в режиме Full-Stack Monitoring¶
Потребление точек данных метрик принимает различные формы. Одинаковое количество точек данных может быть потреблено:
- Несколькими метриками с высоким разрешением или множеством метрик с низким разрешением.
- Равномерно распределённо по нескольким 15-минутным интервалам или сразу в течение одной минуты.
- Всеми отслеживаемыми хостами, подмножеством всех хостов с Full-Stack мониторингом или одним хостом.
Распределённые трассировки¶
Full-Stack Monitoring включает определённый объём данных трассировок. Каждый вносящий вклад ГиБ памяти хоста или приложения добавляет 200 КиБ данных трассировок в минуту, что составляет в общей сложности 3000 КиБ данных трассировок в каждом 15-минутном интервале Среды мониторинга. Этот объём покрывает большинство сценариев использования клиентов. При необходимости клиенты могут явно расширить объём приёма трассировок.
Включённый объём данных трассировок, не использованный в 15-минутном интервале, в котором он был предоставлен, не переносится на последующие интервалы.
Среды, имеющие менее 320 ГиБ памяти, вносящей вклад во включённый объём трассировок, получат фиксированный минимальный пиковый объём 64 000 КиБ/минуту, что эквивалентно 937,5 МиБ в одном 15-минутном интервале.
Данные трассировок Full-Stack Monitoring поступают из двух источников и принимают одну из двух форм.
- Данные трассировок от Dynatrace OneAgent: OneAgent автоматически управляет объёмом захваченных данных трассировок через Adaptive Traffic Management. Он автоматически и непрерывно интеллектуально корректирует частоту выборки и поддерживает объём принимаемых данных трассировок примерно в пределах включённого объёма данных трассировок, что предотвращает непредвиденные расходы.
- Второй источник данных — данные трассировок, отправленные через OneAgent Trace API или, в более общем смысле, трассировки OpenTelemetry, исходящие от хоста или приложения с Full-Stack Monitoring и отправленные через OTLP API. Данные трассировок, отправленные таким образом, могут быть сэмплированы агентом OpenTelemetry, SDK или Collector с фиксированной частотой. Эти механизмы не контролируются Dynatrace или Adaptive Traffic Management. Это означает, что данные трассировок не удерживаются автоматически ниже включённого объёма данных трассировок. Трассировки OpenTelemetry, отправленные таким образом, учитываются в рамках включённого объёма данных трассировок (200 КиБ данных трассировок в минуту), и любые данные трассировок, превышающие включённый объём, тарифицируются как Traces - Ingest & Process.
Обратите внимание, что трассировки, отправленные через Custom Trace API и не исходящие от хоста или приложения с Full-Stack Monitoring, всегда тарифицируются как Traces - Ingest & Process.
Для трассировок OpenTelemetry в этом разделе предполагается, что вы следовали рекомендованным Dynatrace вариантам развёртывания, особенно в отношении обогащения телеметрии. Если вы реализуете пользовательское развёртывание, тарификация включённых трассировок из источников OpenTelemetry может по-прежнему работать как описано, но это не гарантируется Dynatrace.
Для получения дополнительной информации см. Поддерживаемые варианты развёртывания.
Что насчёт включённого объёма трассировок в DPS до Traces powered by Grail
Хотя несжатое количество спанов и трассировок не изменилось, способ их измерения Dynatrace изменился с выпуском Traces powered by Grail. В связи с этим указанный включённый объём трассировок и указанный пиковый объём трассировок для подписок DPS до активации Traces powered by Grail отличаются.
Для DPS без включённого Grail:
- Каждый вносящий вклад ГиБ памяти хоста или приложения добавляет пиковый объём трассировок 45 КиБ/мин.
- Каждая среда имеет минимальный пиковый объём трассировок 14 МиБ/мин.
Пример расчёта пикового объёма трассировок/минуту¶
- Первый 15-минутный интервал:
200 КиБ (пиковый объём трассировок) x 1350 (ГиБ памяти) = 263,67 МиБ/минуту - Второй 15-минутный интервал:
200 КиБ (пиковый объём трассировок) x 950 (ГиБ памяти) = 185,55 МиБ/минуту - Третий 15-минутный интервал:
200 КиБ (пиковый объём трассировок) x 875 (ГиБ памяти) = 170,9 МиБ/минуту - Четвёртый 15-минутный интервал:
200 КиБ (пиковый объём трассировок) x 25 (ГиБ памяти) = 58,6 МиБ/минуту
(В четвёртом 15-минутном интервале фактический объём приёма был бы ниже минимального объёма трассировок, поэтому фактически применяемый лимит равен этому минимуму.)
Включённое и расширенное хранение трассировок¶
Dynatrace хранит все трассировки, принятые из вашей среды, в течение 10 дней.
Dynatrace предоставляет возможность расширить хранение трассировок на выборочной основе до 10 лет, независимо от метода приёма или объёма. Это достигается путём создания пользовательских бакетов в Grail. Первые 10 дней хранения всегда включены. Любые данные трассировок, хранящиеся дольше 10 дней, тарифицируются за гибибайт как Traces - Retain.
Расширенный приём трассировок для Full-Stack Monitoring¶
Full-Stack Monitoring включает определённый объём данных трассировок. Каждый вносящий вклад ГиБ памяти хоста или приложения добавляет 200 КиБ данных трассировок в минуту, что составляет в общей сложности 3000 КиБ данных трассировок в каждом 15-минутном интервале Среды мониторинга.
Dynatrace предоставляет возможность расширить объём данных трассировок, принимаемых с помощью OneAgent. Для этого вы можете запросить увеличенный лимит приёма трассировок сверх 200 КиБ данных трассировок, включённых на гибибайт памяти. Adaptive Traffic Management поддерживает приём трассировок в рамках запрошенного объёма, что предотвращает непредвиденные расходы. (Объяснение Adaptive Traffic Management см. в Распределённые трассировки). Данные трассировок, принятые сверх включённого объёма в 3000 КиБ в данном 15-минутном интервале, тарифицируются как Traces - Ingest & Process.
Дашборд Full-Stack Adaptive Traffic Management and trace capture содержит калькулятор, который поможет вам оценить объём данных на основе желаемого объёма приёма трассировок. Чтобы запросить расширенный приём трассировок для Full-Stack Monitoring, обратитесь к эксперту по продуктам Dynatrace через чат в вашей среде.
Например, ваша текущая частота захвата трассировок составляет 100% большую часть времени, но снижается до 50% в пиковые часы на 2 часа в день. Вы можете запросить 2-кратный лимит объёма приёма трассировок, что повысит его до 400 КиБ на вносящий вклад гибибайт в каждом 15-минутном интервале. В течение этих 2 часов в день вы теперь принимаете вдвое больший объём трассировок. В результате ваша частота захвата трассировок теперь составляет 100% также в пиковые часы. Плата не взимается за 22 часа в день, когда вы уже находились на 100% до изменения. Однако в течение 2 пиковых часов в день примерно половина объёма приёма трассировок будет тарифицироваться как Traces - Ingest & Process.
Профилирование CPU, памяти и потоков¶
Full-Stack Monitoring включает профилирование CPU, памяти и потоков для таких технологий, как Java, .NET, Go, Node.js и PHP. OneAgent использует интеллектуальный запатентованный механизм для управления объёмом данных профилирования. Dynatrace хранит общий объём принятых данных профилирования из вашей среды в течение 10 дней.
Поддерживаемые варианты развёртывания¶
Чтобы ваши трассировки OpenTelemetry и пользовательские метрики использовали включённые объёмы трассировок и метрик, необходимо включить обогащение телеметрии в соответствии с рекомендованными Dynatrace вариантами развёртывания.
Автоматическое обогащение телеметрии включено для:
-
Пользовательских метрик и спанов OpenTelemetry, исходящих от любого:
-
Хоста или контейнера с Full-Stack мониторингом, при использовании OneAgent или выполнении шагов, описанных в Обогащение принимаемых данных полями, специфичными для Dynatrace.
- Контейнера Kubernetes с Full-Stack мониторингом, при использовании Dynatrace Operator с включённым обогащением метаданных.
- Ноды Kubernetes с Cloud-native Full-Stack мониторингом, при использовании Dynatrace Operator с включённым обогащением метаданных. Это включает все контейнеры, работающие на отслеживаемой ноде Kubernetes.
-
Пользовательских метрик, отправленных с любого хоста с Full-Stack мониторингом через локальный API метрик OneAgent. Для получения дополнительной информации см. OneAgent metric API.
-
Трассировок OpenTelemetry, отправленных с любого хоста с Full-Stack мониторингом через локальный API трассировок OneAgent. Для получения дополнительной информации см. Отправка трассировок OpenTelemetry на конечную точку OTLP, предоставляемую OneAgent.
Если вы реализуете пользовательское развёртывание, тарификация трассировок и метрик может по-прежнему работать как описано, но это не гарантируется Dynatrace.
Детали потребления: Full-Stack¶
Dynatrace предоставляет встроенные метрики использования, которые помогают вам понять и проанализировать потребление Full-Stack Monitoring вашей организацией.
Для использования этих метрик в  Data Explorer введите
Data Explorer введите DPS в поле Search.
Эти метрики также доступны через Environment API и в Account Management (Usage summary > Full-Stack Monitoring > Actions > View details).
Ниже приведены метрики, которые вы можете использовать для мониторинга потребления Dynatrace Full-Stack Monitoring.
(DPS) Full-Stack Monitoring billing usage
: Ключ: builtin:billing.full_stack_monitoring.usage
Измерение: count
Разрешение: 15 мин
Описание: Общая память ГиБ всех хостов, отслеживаемых в режиме Full-Stack Monitoring, подсчитанная 15-минутными интервалами.
(DPS) Full-Stack Monitoring billing usage per host
: Ключ: builtin:billing.full_stack_monitoring.usage_per_host
Измерение: Host (`dt.entity.host`)
Разрешение: 15 мин
Описание: Память ГиБ на хост, отслеживаемый в режиме Full-Stack Monitoring, подсчитанная 15-минутными интервалами.
(DPS) Full-stack usage by container type
: Ключ: builtin:billing.full_stack_monitoring.usage_per_container
Измерение: application\_only\_type; k8s.cluster.uid; k8s.namespace.name
Разрешение: 15 мин
Описание: Память ГиБ на контейнер, отслеживаемый в режиме Full-Stack application-only Monitoring, подсчитанная 15-минутными интервалами.
(DPS) Total metric data points reported by Full-Stack monitored hosts
: Ключ: builtin:billing.full_stack_monitoring.metric_data_points.ingested
Измерение: Count
Разрешение: 15 мин
Описание: Количество зарегистрированных точек данных метрик, агрегированных по всем хостам с Full-Stack мониторингом.
(DPS) Metric data points reported and split by Full-Stack monitored hosts
: Ключ: builtin:billing.full_stack_monitoring.metric_data_points.ingested_by_host
Измерение: Host (`dt.entity.host`)
Разрешение: 15 мин
Описание: Количество зарегистрированных точек данных метрик в разрезе хостов с Full-Stack мониторингом.
(DPS) Available included metric data points for Full-Stack monitored hosts
: Ключ: builtin:billing.full_stack_monitoring.metric_data_points.included
Измерение: Count
Разрешение: 15 мин
Описание: Общее количество включённых точек данных метрик, которые могут быть вычтены из потреблённых точек данных метрик, зарегистрированных хостами с Full-Stack мониторингом.
(DPS) Used included metric data points for Full-Stack monitored hosts
: Ключ: builtin:billing.full_stack_monitoring.metric_data_points.included_used
Измерение: Count
Разрешение: 15 мин
Описание: Количество потреблённых включённых точек данных метрик для хостов с Full-Stack мониторингом.
Мониторинг потребления ГиБ-часов памяти для хостов с Full-Stack мониторингом¶
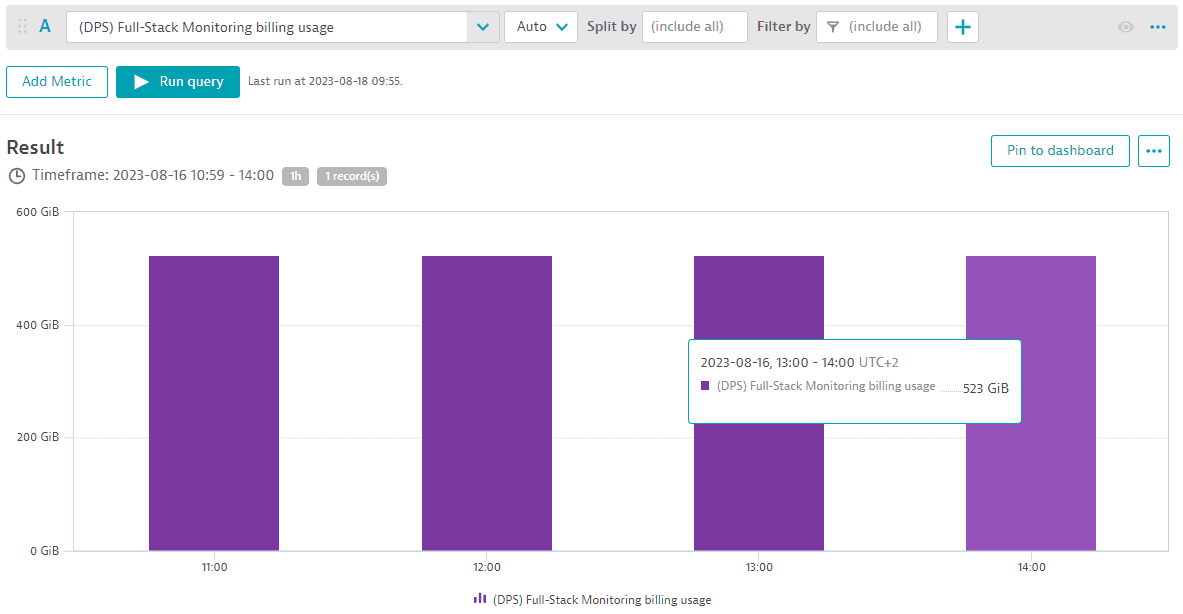
Вы можете отслеживать общее потребление ГиБ-часов памяти, агрегированное по всем хостам с Full-Stack мониторингом, для различных интервалов (15 мин, час, день или неделя) за любой выбранный период времени с помощью метрики «(DPS) Full-Stack Monitoring billing usage». Пример ниже показывает ГиБ памяти, отслеживаемые 1-часовыми интервалами. Между 11:00 и 14:00 каждый час отслеживалось 523 ГиБ памяти. Это приводит к потреблению 523 ГиБ-часов памяти.
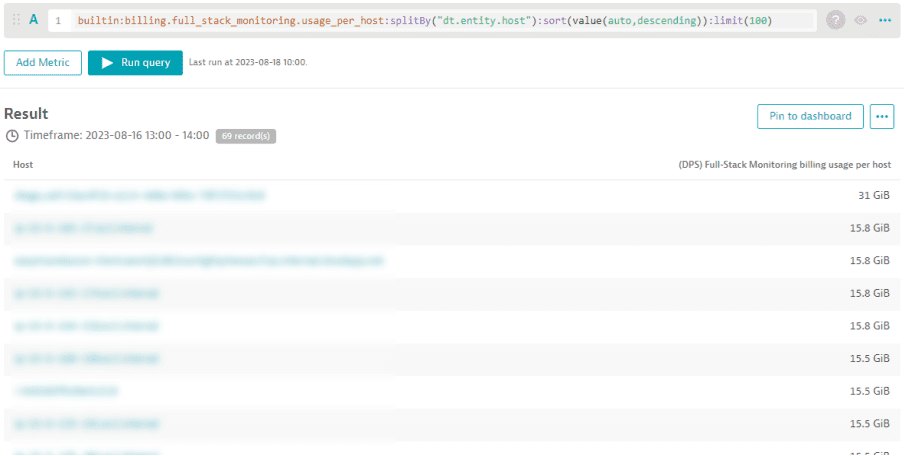
Вы можете детализировать общее потребление ГиБ-часов памяти с помощью метрики «(DPS) Full-Stack Monitoring billing usage per host». Пример ниже показывает список всех хостов, которые внесли вклад в потребление 523 ГиБ-часов памяти между 13:00 и 14:00. Соответствующее количество ГиБ-часов памяти на хост также отображается.
Мониторинг потребления ГиБ-часов памяти для контейнеров с Full-Stack мониторингом¶
Владельцы платформ и кластеров могут отслеживать свои кластеры Kubernetes с помощью Kubernetes Platform Monitoring."). Владельцы приложений могут использовать Full-Stack Monitoring на основе контейнеров для мониторинга приложений, работающих в кластерах Kubernetes.
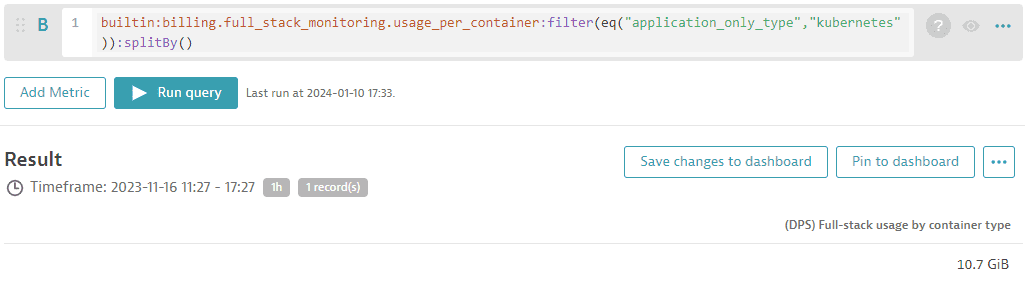
Для получения информации о потреблении отслеживаемых кластеров или пространств имён Kubernetes вы можете запросить потребление ГиБ-часов памяти, используя метрику «(DPS) Full-Stack Monitoring billing usage per container», как показано в следующем запросе:
builtin:billing.full_stack_monitoring.usage_per_container:filter(eq("application_only_type","kubernetes")):splitBy()
В примере ниже 1,58 ТиБ памяти было потреблено кластером Kubernetes за последние 30 дней.
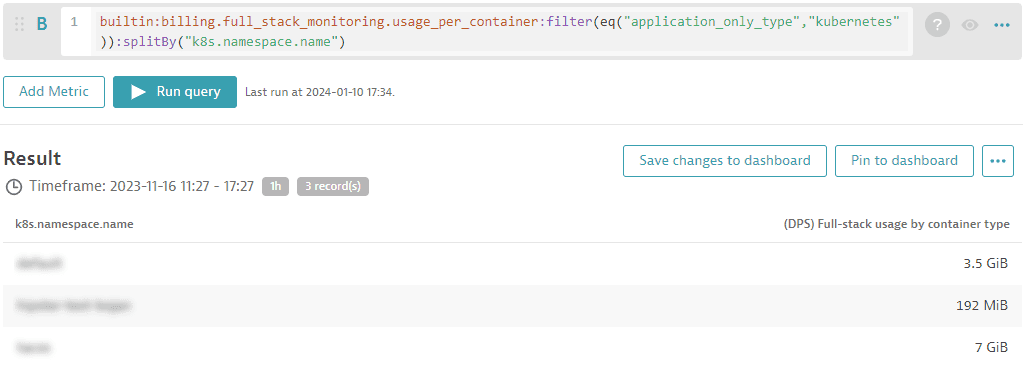
Конечно, вы можете фильтровать анализ для более глубоких выводов (например, добавить разбивку по пространствам имён Kubernetes).
Мониторинг потребления метрик для хостов с Full-Stack мониторингом¶
Для мониторинга бюджета метрик для всего пула точек данных метрик в вашей среде вы можете отслеживать доступные включённые точки данных метрик в сравнении с общим количеством зарегистрированных точек данных метрик, используя две метрики: «(DPS) Available included metric data points for Full-Stack monitored hosts» и «(DPS) Total metric data points reported by Full-Stack monitored hosts». Пример ниже показывает данные за полный день. Ни в один момент времени количество включённых метрик для пула метрик этой среды (фиолетовая линия) не было перерасходовано.
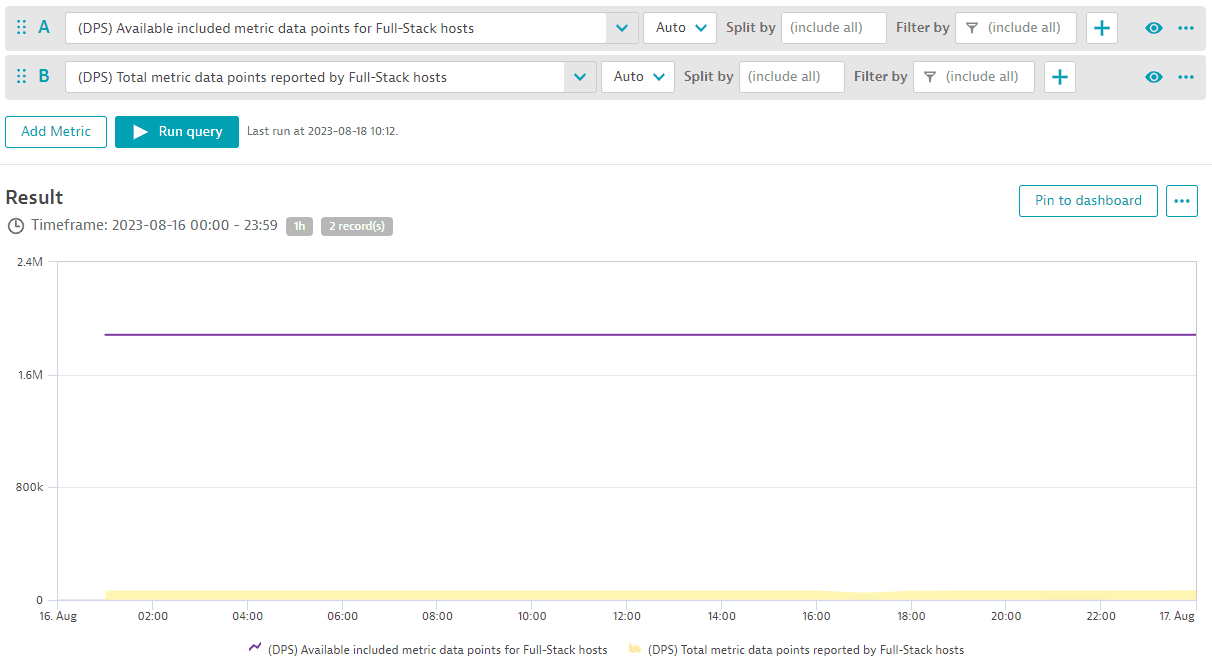
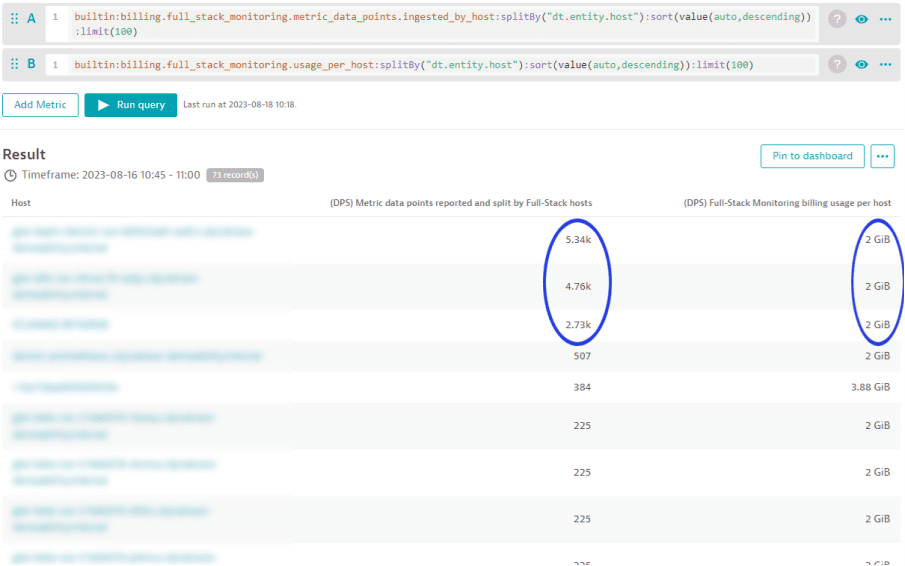
В случаях, когда количество включённых метрик для пула метрик среды перерасходовано, следующий анализ может помочь вам определить хосты, которые вносят вклад в перерасход. Используйте метрику «(DPS) Metric data points reported and split by Full-Stack monitored hosts» для этого анализа.
Пример ниже показывает, что между 10:45 и 11:00 каждый из первых 3 хостов в списке зарегистрировал значительно более 2000 точек данных метрик. В тот же период каждый из этих 3 хостов показывает потребление ГиБ-часов памяти в 2 ГиБ. Dynatrace предлагает 900 включённых пользовательских точек данных метрик для каждого ГиБ памяти хоста, рассчитанных 15-минутными интервалами. Это означает, что первые 3 хоста вносят 1800 (2*900) точек данных метрик в пул доступных точек данных среды. Однако эти хосты потребили больше точек данных, чем они внесли за тот же период времени.
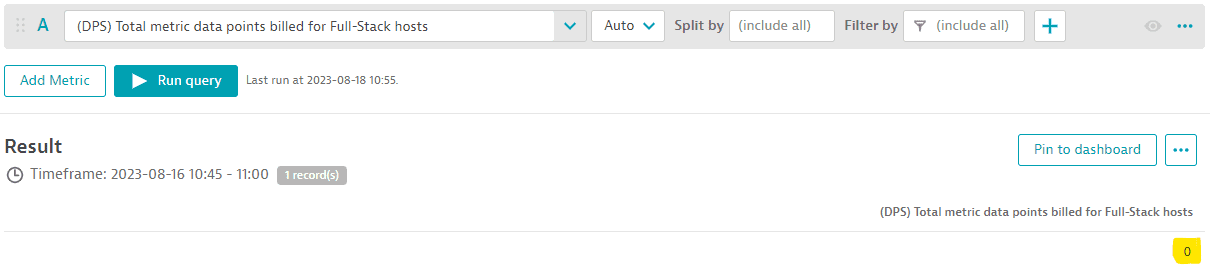
При использовании метрики «(DPS) Total metric data points billed for Full-Stack monitored hosts» из Custom Metrics Classic видно, что перерасхода для пула метрик Full-Stack Monitoring этой среды между 10:45 и 11:00 не произошло, поскольку ни одна точка данных метрик не была тарифицирована.
Связанные темы¶
- Dynatrace OneAgent
- Обзор Application & Infrastructure Observability (DPS).")
- Ценообразование Dynatrace