Предиктивный ИИ-анализ Dynatrace Intelligence
- Описание
Анализ прогнозирования предсказывает будущие значения любого временного ряда числовых значений. Анализатор прогнозирования не ограничен хранимыми данными метрик — вы можете использовать собственные данные, запрос метрик или запрос данных, который возвращает временной ряд числовых значений.
Анализ не зависит от распределения входных данных. Прогноз рассчитывается без каких-либо предположений о конкретном распределении данных и работает как для симметричных, так и для несимметричных распределений.
Вы можете запустить анализ прогнозирования из вашего ноутбука.
Входные данные анализатора¶
Методология анализа¶
Когда вы запускаете анализ прогнозирования, временной ряд отправляется соответствующему прогнозатору, который создаёт прогноз. Затем оценивается качество прогноза, и прогноз вместе с оценкой возвращаются в качестве результатов анализа.
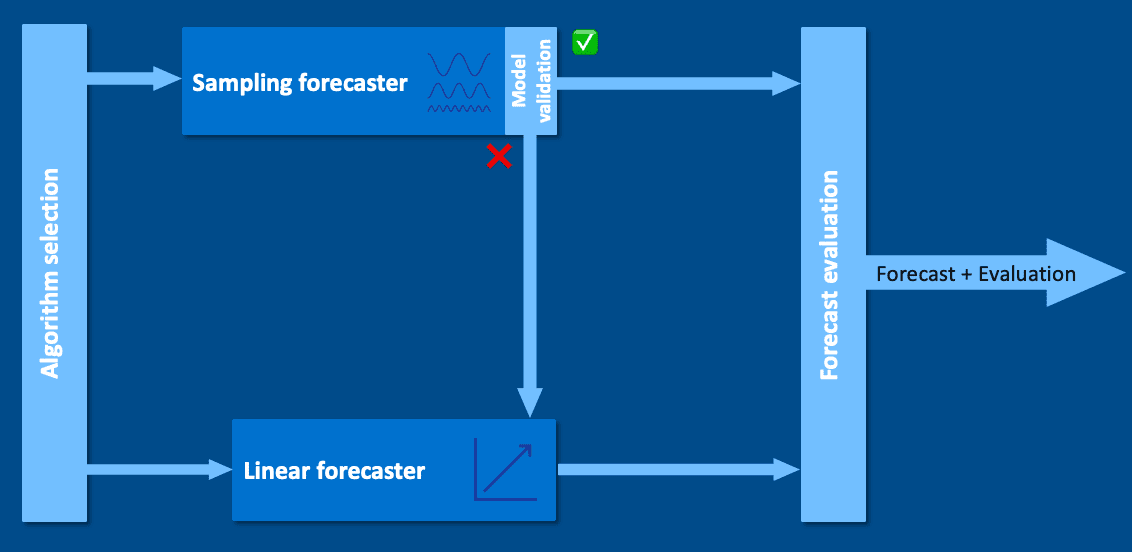
Выбор алгоритма¶
Анализ использует один из двух прогнозаторов:
Прогнозатор на основе выборки используется, если дисперсия линейного исторического временного окна больше максимального значения из пары 0.1 и 0.001 * дисперсия входного временного ряда. Линейное историческое временное окно — это X последних точек данных, где X находится в диапазоне от 14 до 20.
Во всех остальных случаях (включая случай, когда обучение прогнозатора на основе выборки завершается неудачей) используется прогнозатор линейной экстраполяции.
Прогнозатор на основе выборки¶
Прогнозатор на основе выборки обеспечивает многошаговое прогнозирование на основе сезонных паттернов. Его архитектура показана на изображении ниже.
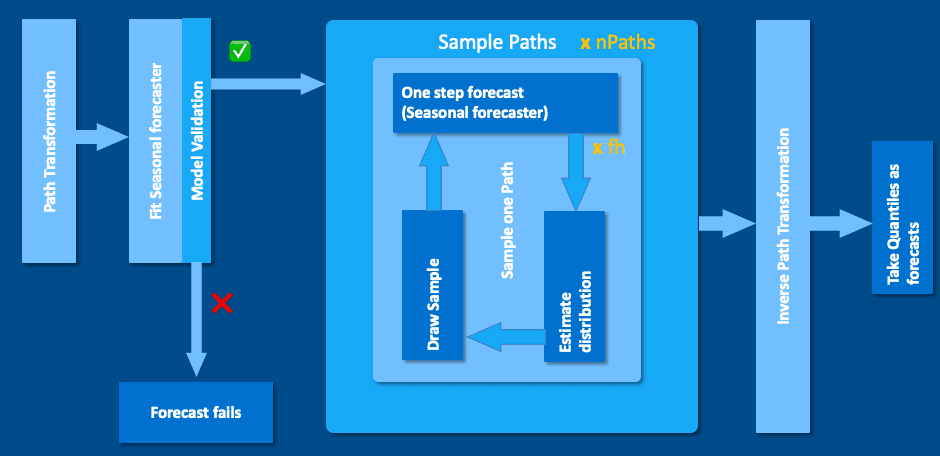
Сначала к входному временному ряду применяется преобразователь пути, а затем на нём обучается прогнозатор. Если полученная модель недействительна, вместо неё используется прогнозатор линейной экстраполяции. Если модель действительна, сезонный прогнозатор создаёт пути выборки. Затем эти пути подвергаются обратному преобразованию перед применением квантилей на каждом временном шаге.
Сезонные паттерны¶
Прогнозатор всегда ищет различные сезонные паттерны во входном временном ряде. Входной временной ряд должен содержать достаточно данных для надёжного обнаружения сезонности.
| Сезонный паттерн | Требуемая длительность временного ряда |
|---|---|
| 1 час | 2+ часов |
| 1 день (24 часа) | 7+ дней |
| 1 неделя (7 дней) | 14+ дней |
| День недели | 7+ дней |
| Время суток | 2+ дней |
| Минута часа | 2+ часов |
Помимо этих естественных паттернов, прогнозатор ищет любые повторяющиеся паттерны во временном ряде, разбивая их на основе определённого временного окна.
Пошаговый прогноз¶
- Сезонный прогнозатор оценивает квартили распределения временного ряда в момент времени следующей точки данных.
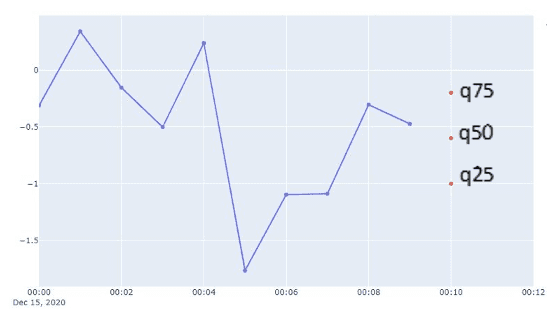 2. Распределение значения на следующем временном шаге оценивается по квартилям. Колокольная кривая на изображении приведена для наглядности и не представляет распределение, используемое в прогнозаторе на основе выборки.
2. Распределение значения на следующем временном шаге оценивается по квартилям. Колокольная кривая на изображении приведена для наглядности и не представляет распределение, используемое в прогнозаторе на основе выборки.
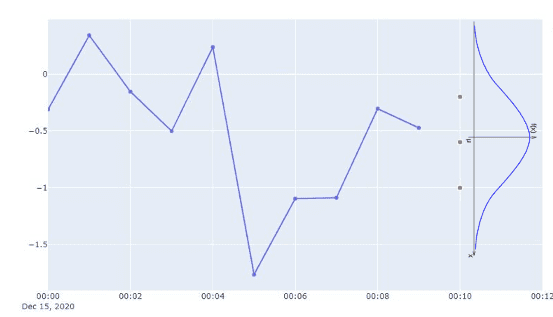 3. Значение для следующего временного шага выбирается из распределения, полученного на шаге 2.
3. Значение для следующего временного шага выбирается из распределения, полученного на шаге 2.
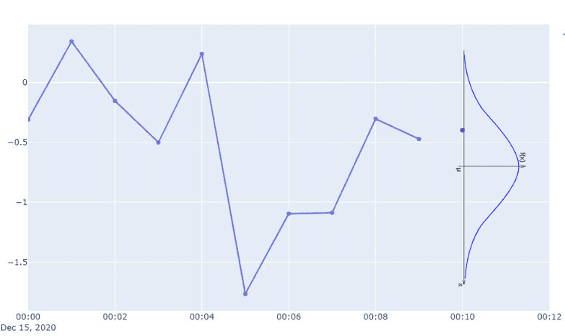 4. Значение, полученное на шаге 3, теперь считается частью временного ряда, и прогнозатор повторяет шаги 1-4, пока не достигнет горизонта прогнозирования.
4. Значение, полученное на шаге 3, теперь считается частью временного ряда, и прогнозатор повторяет шаги 1-4, пока не достигнет горизонта прогнозирования.
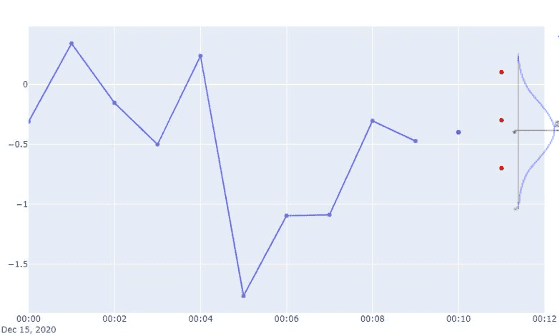 5. Предсказанные точки данных формируют один путь выборки (показан красным на изображении ниже).
5. Предсказанные точки данных формируют один путь выборки (показан красным на изображении ниже).
 6. Прогнозатор повторяет этот процесс N раз, создавая несколько путей выборки.
6. Прогнозатор повторяет этот процесс N раз, создавая несколько путей выборки.
 7. Прогнозатор берёт искомый квантиль на каждом временном шаге, формируя интервал предсказания (показан светло-фиолетовым на изображении ниже).
7. Прогнозатор берёт искомый квантиль на каждом временном шаге, формируя интервал предсказания (показан светло-фиолетовым на изображении ниже).

Прогнозатор линейной экстраполяции¶
Прогнозатор линейной экстраполяции — это алгоритм, который использует простую линейную регрессию для нахождения наилучшей подходящей линии через набор точек данных и продления этой линии в будущее. Количество точек данных, используемых для обучения прогнозатора, определяется следующим образом
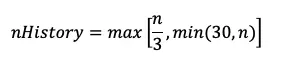
где n — длина входного временного ряда.
Для обучения прогнозатора линейной экстраполяции nHistory должен содержать не менее 14 ненулевых точек данных.
Для простоты мы рассчитываем доверительный интервал, предполагая, что остатки нормально распределены, следующим образом:
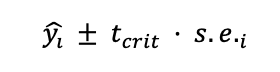
где tcrit — это 95-й процентиль t-распределения Стьюдента. Стандартная ошибка равна
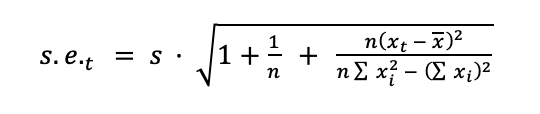
где X̄ — среднее значение x, суммы берутся по обучающим данным, а s — выборочная стандартная ошибка последних nHistory точек входного временного ряда.
Оценка качества прогноза¶
После генерации предсказаний мы оцениваем их качество для выявления потенциальных числовых проблем. Для оценки качества прогноза анализатор сравнивает стандартное отклонение предсказания со стандартным отклонением входного временного ряда (SDinput).
Стандартное отклонение предсказаний (SDprediction) рассчитывается как максимальное стандартное отклонение нижней и верхней границ интервала предсказания, а также стандартное отклонение точечного предсказания.
Для учёта допустимых трендов в предсказаниях анализатор использует коэффициент масштабирования (SCF). Когда длина данных предсказания (Nprediction) велика по сравнению с входным временным рядом (Ninput), мы допускаем большее стандартное отклонение предсказания, чем для малого предсказания.
Дополнительным входным параметром для коэффициента масштабирования является Фактор стандартного отклонения (SDfactor) со значением по умолчанию 100. Коэффициент масштабирования рассчитывается следующим образом:
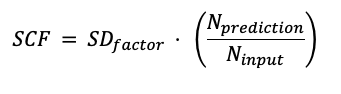
Прогноз оценивается по следующему условию:
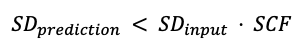
Если условие выполняется, прогноз оценивается как действительный. В противном случае прогноз недействителен.
Написание DQL-запросов для прогнозирования¶
При использовании анализа прогнозирования в одном из ваших ноутбуков вы можете написать любой DQL-запрос, который возвращает данные временного ряда в формате записи временного ряда.
- Если данные не соответствуют одному из вышеуказанных форматов, анализ прогнозирования завершится с ошибкой.
- Каждое числовое значение в массиве данных должно иметь хотя бы одну десятичную точку (например,
1.0).
Примеры запросов¶
Приведённые ниже примеры DQL-запросов возвращают корректные ответы.
- Команда DQL
timeseriesвсегда возвращает ответ в формате записи временного ряда. - Вы также можете писать запросы, используя команду
fetchвместе с командойsummarize. Эти запросы возвращают данные в формате единичного значения. Все записи должны иметь одинаковое расстояние (интервал) между ними. Это гарантируется при использовании командыsummarize, так как она агрегирует и группирует значения для определённых временных корзин. Каждая запись должна иметь поле с именемvalueтипа double (подробнее см. Формат единичного значения).
Команда DQL timeseries¶
Команда DQL timeseries возвращает результат в формате записи временного ряда.
Запрос DQL fetch и summarize¶
DQL-запрос с использованием команд fetch и summarize возвращает результат в формате единичного значения.
fetch events, from: -3d
| filter event.kind == "DAVIS_PROBLEM"
| summarize count(), by:{bin(timestamp, 1h), alias: timestamp}
| fieldsRename value=`count()`
Команда DQL data¶
Вы можете использовать команду DQL data для создания прогноза на основе собственных данных. Можно использовать любые данные, при условии что они соответствуют одному из двух форматов.
Следующая команда DQL data возвращает результат в формате записи временного ряда.
data record(
timeframe=timeframe(from: "2023-03-10T00:00:00.000Z", to: "2023-03-20T00:00:00.000Z"),
interval=duration(1, "h"),
`dt.entity.disk`="DISK-A",
data=array(
0.6096, 1.1460, 1.2770, 2.3939, 2.2370, 2.6167, 1.2414,
3.0011, 2.6842, 2.2949, 1.4132, 1.7749, 1.6472, 0.5800,
0.2937, 0.8003, -0.0277, -0.4114, -0.6020, -0.5019, 0.2261,
0.9875, 0.9601, 1.7021, 2.7538, 3.2475, 3.4133, 3.6173,
4.2067, 4.8679, 4.4176, 4.7181, 5.1461, 5.0898, 4.9806,
3.7390, 3.3774, 2.4088, 2.6754, 2.7673, 1.7551, 1.9633,
1.5918, 2.4702, 2.5765, 2.8267, 3.4773, 3.8841, 5.4904,
5.6528, 5.6221, 7.0052, 6.7039, 8.8618, 7.2853, 7.5175,
7.2200, 7.5092, 7.2807, 6.3166, 6.4115, 5.1241, 5.2359,
5.6137, 4.5477, 5.2841, 4.8689, 6.1404, 4.3398, 4.7527,
5.6016, 6.7526, 7.0054, 8.4009, 7.3848, 9.0195, 9.6028,
10.0891, 10.3137, 9.9700, 8.9944, 9.4415, 9.4228, 8.1233,
8.5862, 8.4357, 8.0413, 7.1731, 6.9146, 6.6773, 6.7132,
7.0178, 7.4880, 7.1100, 9.5785, 8.6518, 9.2125, 10.2238,
11.4487, 11.1977, 11.3190, 12.5375, 11.9569, 12.4308, 11.7920,
12.6200, 12.0601, 10.5243, 11.3639, 9.8979, 10.9811, 10.1095,
10.2067, 9.6794, 9.8522, 9.0232, 9.5124, 10.5887, 11.0222,
10.8741, 12.0817, 13.3625, 13.1324, 13.5550, 13.7834, 14.1806,
15.5751, 14.7827, 13.9171, 14.5871, 14.5652, 13.4159, 13.6262,
12.3931, 11.9045, 12.2807, 10.9243, 12.5514, 11.0550, 12.1066,
12.1569, 12.9026, 12.9851, 13.5527, 14.9463, 14.5251, 15.6653,
17.1333, 17.5200, 17.4643, 17.3053, 16.9866, 16.6806, 16.4379,
16.2866, 16.9108, 15.3212, 15.4509, 14.5511, 14.8598, 15.4171,
14.2590, 14.5359, 14.4026, 15.5683, 14.8414, 15.5065, 15.7033,
17.1206, 17.4528, 17.5131, 19.2782, 18.6581, 20.6962, 20.4152,
18.5865, 19.3483, 18.8283, 18.9540, 17.4941, 17.8047, 18.7973,
17.1900, 16.1135, 17.0345, 17.1779, 16.6910, 16.8454, 16.9357,
17.3166, 17.9157, 18.8126, 18.8176, 19.9470, 20.5230, 21.2858,
22.2686, 22.2769, 21.1908, 21.8713, 21.2280, 20.8140, 21.7997,
20.5656, 20.2129, 20.1171, 19.6284, 18.9140, 18.8314, 19.1833,
18.4992, 19.0013, 20.0113, 20.4361, 20.2264, 21.7505, 22.0324,
22.7636, 22.3307, 24.1297, 24.1968, 24.0366, 23.8212, 24.5346,
24.2898, 24.0449, 23.8067, 22.9443, 23.3615, 22.5078, 22.1239,
21.9639, 21.9736, 21.8018, 21.5930, 21.5247, 21.7674, 22.7781,
23.6532, 23.1769
)
)
Формат записи временного ряда¶
В формате записи временного ряда временные ряды определяются как простые массивы double.
- В одной записи может быть несколько массивов и несколько отдельных записей.
- Корректный ответ временного ряда содержит только записи временных рядов.
Запись временного ряда должна содержать:
- Ровно одно поле типа timeframe, содержащее начальную и конечную временную метку
- Ровно одно поле типа duration
-
Одно или более полей типа
array, содержащих только значения double или long и null -
Все числовые массивы должны содержать столько значений, сколько временных шагов шириной duration помещается между началом и концом временного окна
(end-start)/duration - Поля в записи временного ряда, отличные от timeframe, duration и числовых массивов данных, считаются измерениями
Ответ DQL в формате записи временного ряда
Следующий JSON описывает структуру формата записи.
- Типы полей записи указаны в разделе
types. - Фактическое значение поля типа duration задаётся в наносекундах.
{
"records": [
{
"timeframe": {
"start": "2023-01-01T00:00Z",
"end": "2023-01-01T00:05Z"
},
"firstTimeSeries": [1.0, 3.0, 5.0, 7.0, 9.0],
"secondTimeSeries": [0.0, 2.0, 4.0, 6.0, 8.0],
"interval": "60000000000",
"dt.metricKey": "host.cpu.usage"
}
],
"types": [
{
"indexRange": [0, 0],
"mappings": {
"dt.entity.host": { "type": "string" },
"dt.metricKey": { "type": "string" },
"timeframe": { "type": "timeframe" },
"interval": { "type": "duration" },
"firstTimeSeries": {
"type": "array",
"types": [
{
"indexRange": [0, 4],
"mappings": {
"element": { "type": "double" }
}
}
]
},
"secondTimeSeries": {
"type": "array",
"types": [
{
"indexRange": [0, 4],
"mappings": {
"element": { "type": "double" }
}
}
]
}
}
}
]
}
Формат единичного значения¶
В формате единичного значения каждая запись определяет одно значение во временном ряде. Допускается ровно одно числовое поле на запись.
Запись в корректном ответе формата единичного значения должна содержать:
- Ровно одно поле с именем
valueтипа double или long -
Информацию о времени в одном из форматов:
-
поле с именем
timestampтипа timestamp - поле с именем
timeframeтипаtimeframe, содержащее начальную и конечную временную метку
Интервал¶
Минимально допустимый интервал (разница во времени между двумя записями) составляет одну минуту.
- Интервал можно указать, добавив поле
intervalтипа duration. - Это поле также может называться
frequency, хотяintervalимеет приоритет, если указаны оба. - Если
interval/frequencyзадан, он должен иметь одинаковое значение в каждой записи.
Измерения¶
Измерения могут быть добавлены как дополнительные свойства.
- Дополнительные свойства могут иметь только строковые значения.
- Ряд определяется на основе уникальных значений для каждого измерения. Записи с одинаковыми измерениями (строковыми свойствами) считаются принадлежащими одному временному ряду.
Ответ DQL в формате единичного значения
Следующий JSON описывает структуру формата единичного значения.
- Типы полей записи указаны в разделе
types. - Фактическое значение поля типа duration задаётся в наносекундах.
{
"records": [
{
"timestamp": "2019-05-14T08:01Z",
"interval": "60000000000",
"dt.metricKey": "host.cpu.usage",
"value": 0.0
},
{
"timestamp": "2019-05-14T08:02Z",
"interval": "60000000000",
"dt.metricKey": "host.cpu.usage",
"value": 2.0
},
{
"timestamp": "2020-05-14T08:03Z",
"interval": "60000000000",
"dt.metricKey": "host.cpu.usage",
"value": 4.0
}
],
"types": [
{
"indexRange": [0, 2],
"typeMappings": {
"timestamp": { "type": "timestamp" },
"interval": { "type": "duration" },
"dt.metricKey": { "type": "string" },
"value": { "type": "double" }
}
}
]
}
{
"records": [
{
"timeframe": {
"start": "2019-12-09T12:00Z",
"end": "2019-12-09T13:00Z"
},
"interval": "3600000000000",
"dt.metricKey": "host.cpu.usage",
"dt.entity.host": "HOST-A",
"value": 0.0
},
{
"timeframe": {
"start": "2019-12-09T13:00Z",
"end": "2019-12-09T14:00Z"
},
"interval": "3600000000000",
"dt.metricKey": "host.cpu.usage",
"dt.entity.host": "HOST-A",
"value": 2.0
}
],
"types": [
{
"indexRange": [0, 2],
"typeMappings": {
"timeframe": { "type": "timeframe" },
"interval": { "type": "duration" },
"dt.metricKey": { "type": "string" },
"dt.entity.host": { "type": "string" },
"value": { "type": "double" }
}
}
]
}
Примеры прогнозов¶
Качество прогноза зависит от качества данных, подаваемых анализатору, и ширины временного окна, которое вы хотите предсказать. Лучшие результаты получаются для короткого временного окна из данных без шума и с чёткими сезонными паттернами. Ниже приведены примеры прогнозов для различных типов данных.
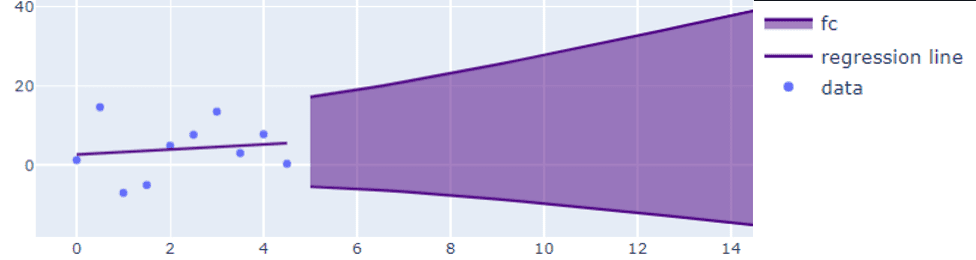
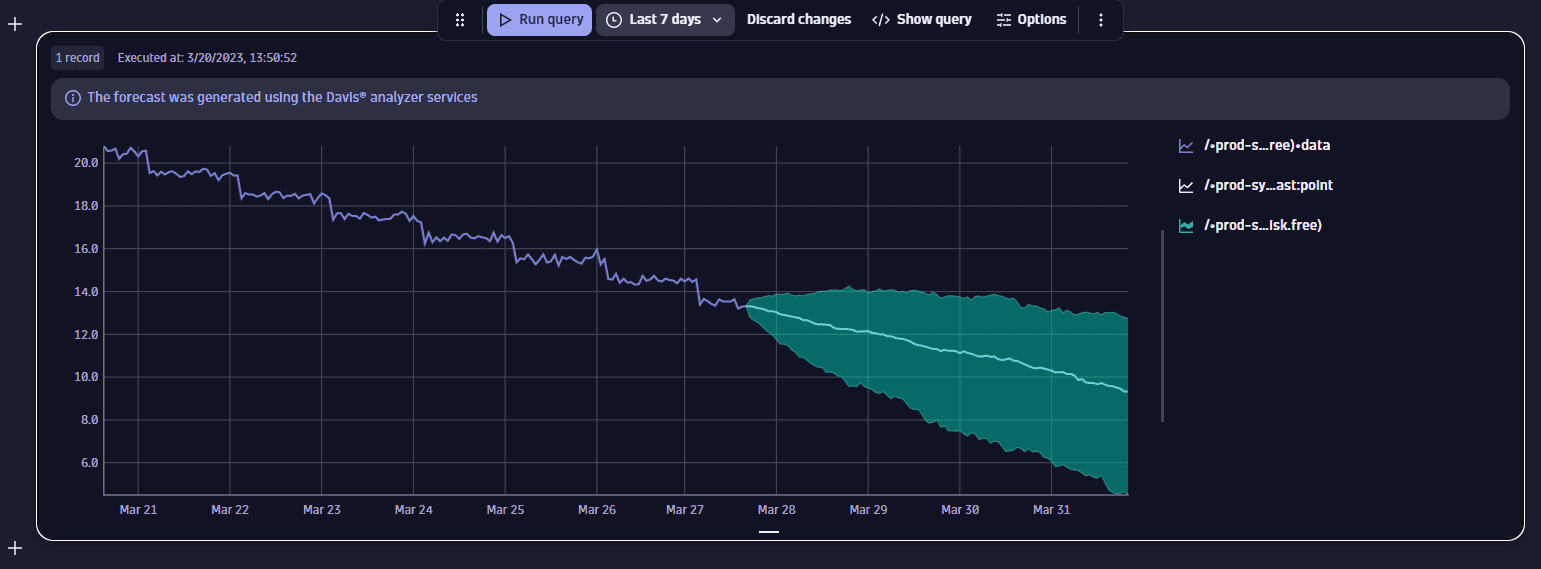
Без сезонности, нисходящий тренд
Этот пример показывает прогноз для метрики доступного дискового пространства. В данных нет сезонного паттерна, и присутствует нисходящий тренд. Здесь используется прогнозатор линейной экстраполяции, создающий широкий прогнозируемый интервал.
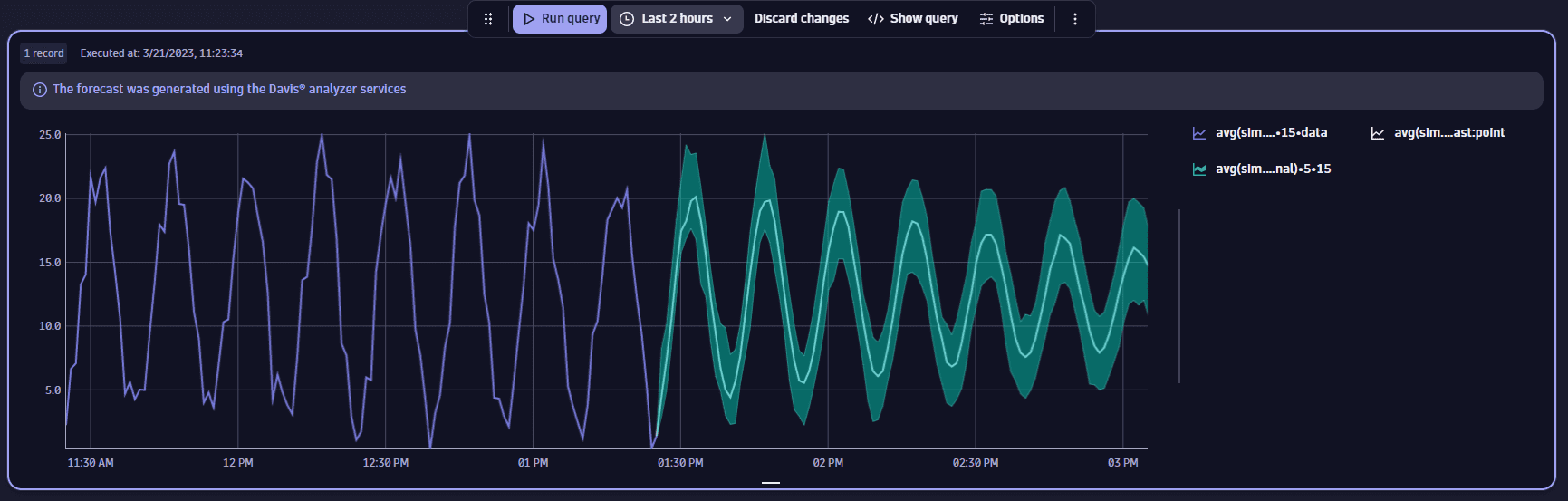
Сезонные данные с шумом
Этот пример показывает прогноз для временного окна в 1,5 часа. Обратите внимание, что прогнозируемый интервал не является гладким, что отражает шум во входных данных.
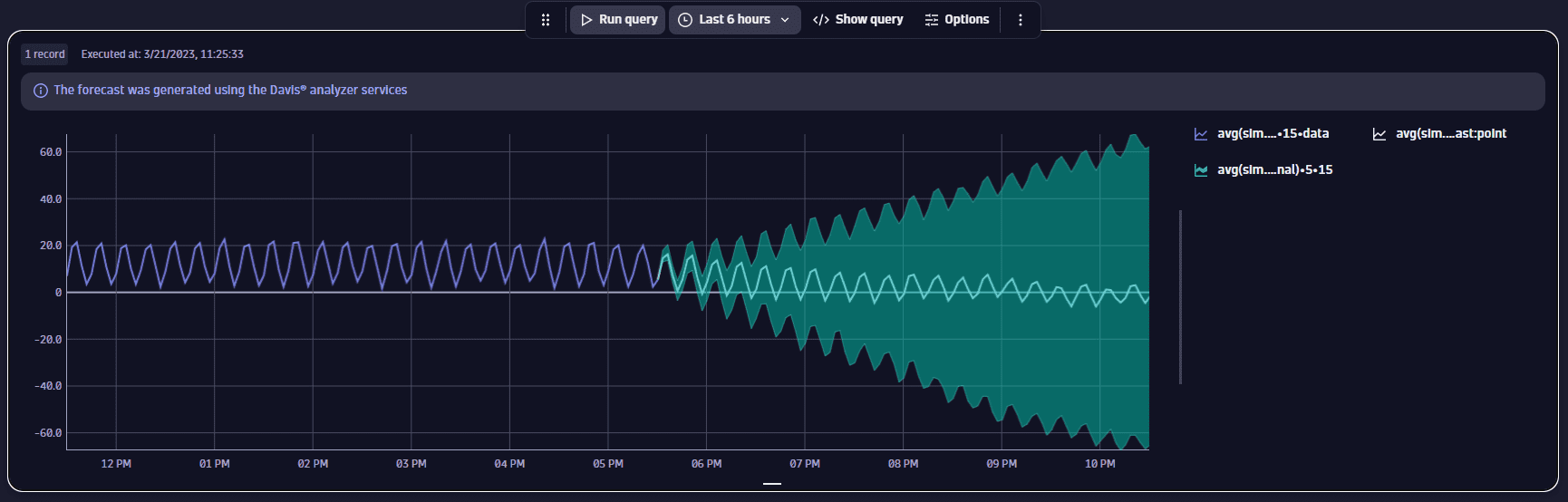
Сезонные данные с шумом на расширенном временном окне
Этот пример показывает прогноз для 6-часового временного окна. Помимо обширного временного окна прогноза, сами данные содержат некоторый шум и нисходящий тренд, которые влияют на качество прогноза — прогнозируемый интервал расширяется всё больше по мере продвижения в будущее.